Scraping TripAdvisor
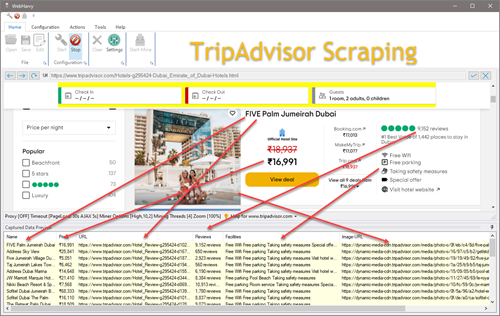
The video displayed below shows how WebHarvy can be configured to scrape data from TripAdvisor hotels and restaurants listings. Details like name, price, ratings and reviews, rank, address, contact details (phone, email, address) and hotel/room details can be scraped for multiple listings automatically using WebHarvy.
WebHarvy Settings for TripAdvisor Scraping
The following values in WebHarvy settings need to be changed before attempting TripAdvisor scraping. Without these changes mining might stop after a few records or pages of data owing to TripAdvisor's anti scraping initiatives.
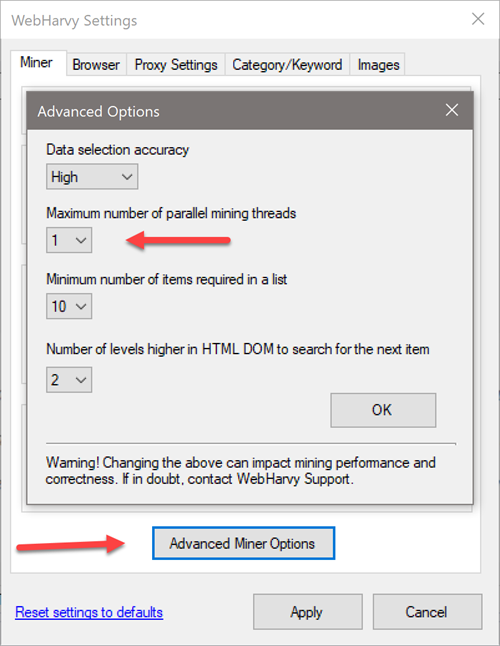
Open WebHarvy setting and click on Advanced Miner Options button. In the resulting window select value 1 for Maximum number of parallel mining threads.
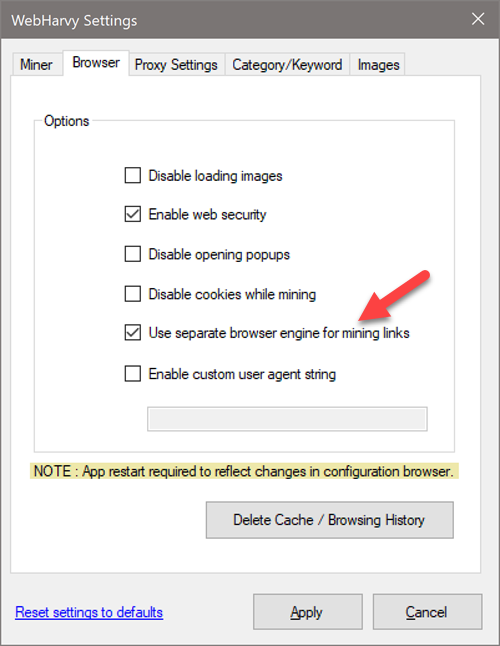
Go to the Browser tab of Settings window and enable the Use separate browser engine for mining links option as shown below. Then Apply changes.
Since these settings are specific to TripAdvisor website, make sure that you reset settings to default values before attempting to scrape other websites.
Configuring WebHarvy for TripAdvisor Scraping
Load the TripAdvisor page from which you need to extract data within WebHarvy's configuration browser. Once the page is loaded you can start the configuration process by clicking on the Start button. Now, you can click and select each data item which you need to scrape. It is always recommended to ignore sponsored listings or ads while selecting data - select data from the first non-ad or non-sponsored listing.
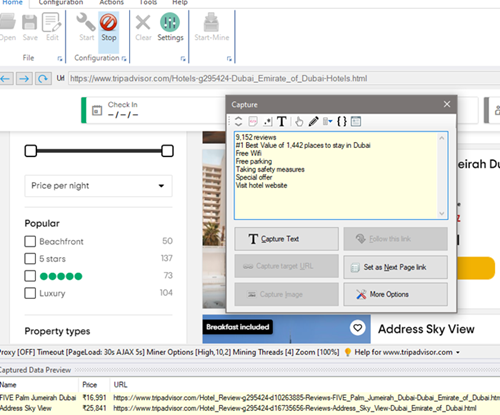
During configuration, when you click on any content (text or image) within the page, WebHarvy will display a Capture window with various options. You can select data, scrape multiple pages of listings, follow each listing link etc. using options provided in this Capture window.
Try WebHarvy
We recommend that you download and try the evaluation version of WebHarvy and also watch the basic demonstration videos.
Download the FREE evaluation version of WebHarvy
Need Support ?
In case you need assistance in configuring WebHarvy, please do not hesitate to contact our support team (support@webharvy.com) with the details (URL of the webpage + details of the data to be scraped). We are happy to help you get started with your first data extracting project using WebHarvy !