In this article, we will see how to scrape Amazon product data using WebHarvy. WebHarvy can be used to scrape data from any website using a very intuitive and easy to use, point and click user interface. WebHarvy can be downloaded and locally installed on your computer.
WebHarvy contains a built-in browser which can be used to load and navigate web pages. Data to be scraped can be selected by simply clicking on them. WebHarvy automatically identifies similar data items and scrapes them. It also supports pagination and following links to scrape data from multiple pages.
How to scrape Amazon Product Data using WebHarvy?
Video displayed below demonstrates the steps involved in scraping Amazon product data using WebHarvy.
Given below are the steps which you need to follow, as shown in the above video.
1. Download and Install WebHarvy
Download and install the free evaluation version of WebHarvy on your computer.
2. Load Page and Start Configuration
Load the Amazon product listings page from which you need to scrape data within WebHarvy's configuration browser and start configuration.
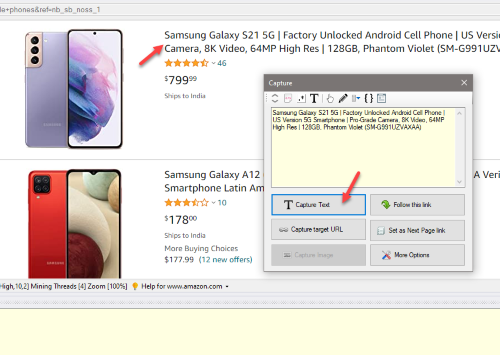
3. Select Product Details
Click and select the product details which you need to scrape. Details like product name, price, URL, images etc. can be directly clicked and selected for extraction. When you click over any text or image displayed on the page, WebHarvy will display a Capture window with various options. Select the 'Capture Text' option to select the text of the item for scraping.
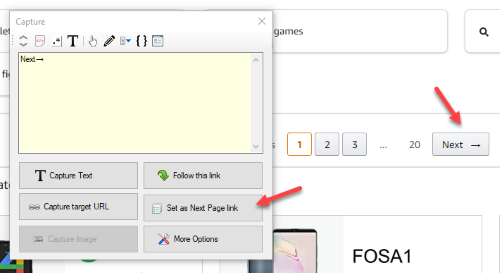
4. Select Pagination Link
Product listings span across multiple pages, this is called pagination. Pagination can be configured by clicking on the link to load the next page of listings and by selecting the 'Set as Next Page link' option from the Capture window. This allows WebHarvy to automatically load and scrape data from multiple pages of product listings.
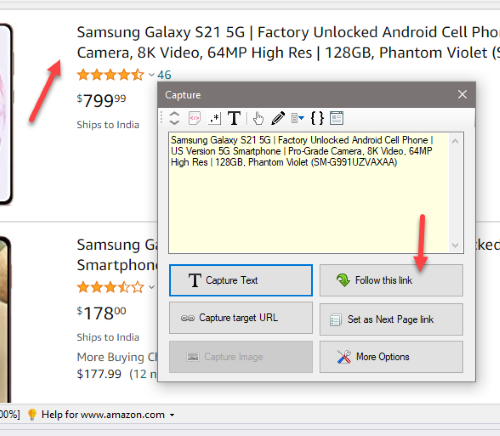
5. Follow Links and Select More Details
WebHarvy allows you to follow each product link and scrape additional data. Click on the title link of the first product, and select the Follow this link option from the resulting Capture window.
Once the product details page is loaded, use the Capture following text option, whenever the text to scrape appears after a heading text, to correctly select data irrespective of its relative position on the page. Details like ASIN, Best Sellers Rank, item model number, item weight etc. can be selected in this manner.
6. Mine data
Once you have selected all the required data to scrape, Stop Configuration and Start Mining. Scraped product data can be saved to a file or database.
Download and Try
We recommend that you download and try the free evaluation version of WebHarvy. If you have any questions, please feel free to contact our technical support team.