This article explains how WebHarvy can be used to scrape name, address, email address and phone number of businesses from Yellow Pages Australia listings.
Steps to follow to scrape Yellow Pages Australia using WebHarvy
First download and install WebHarvy in your computer. We offer a 15 days free evaluation version in case you do not have a paid license account.
WebHarvy contains a built-in web browser using which you can load and navigate web pages.
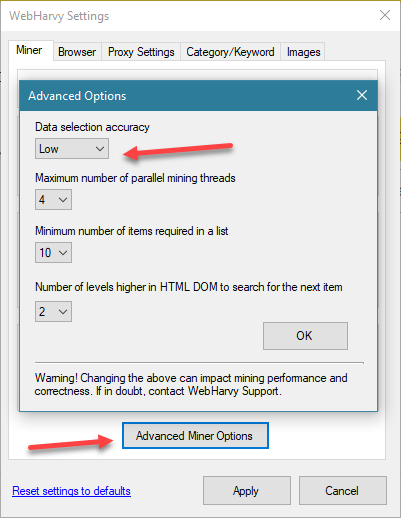
To scrape Yellow Pages Australia you need to make the following Settings change in WebHarvy. Open WebHarvy Settings, click on 'Advanced Miner Options' button and select the value Low for 'Data selection accuracy'. Apply Changes.
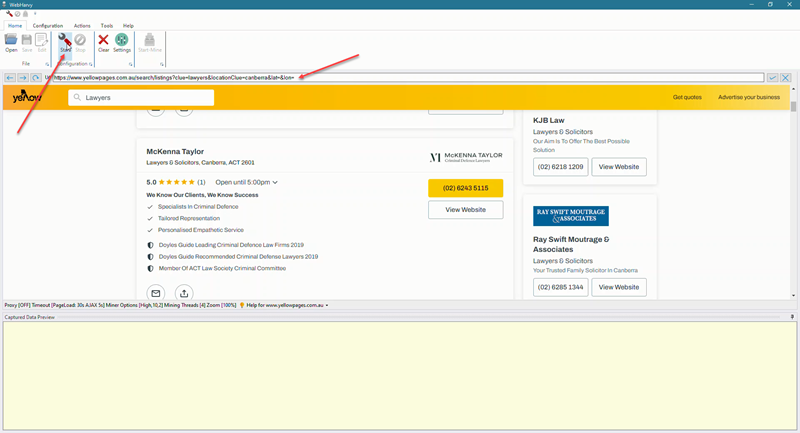
After making the above change, load the yellow pages listings page from which you need to extract data within WebHarvy's browser and click the Start configuration button.
After starting configuration, click anywhere on the page and select More Options > Run Script from the resulting Capture window. In the resulting window, paste and apply the following code.
el =
document.getElementsByClassName('Box__Div-sc-dws99b-0
iTBdGC jss263')[0]; el.parentElement.removeChild(el);
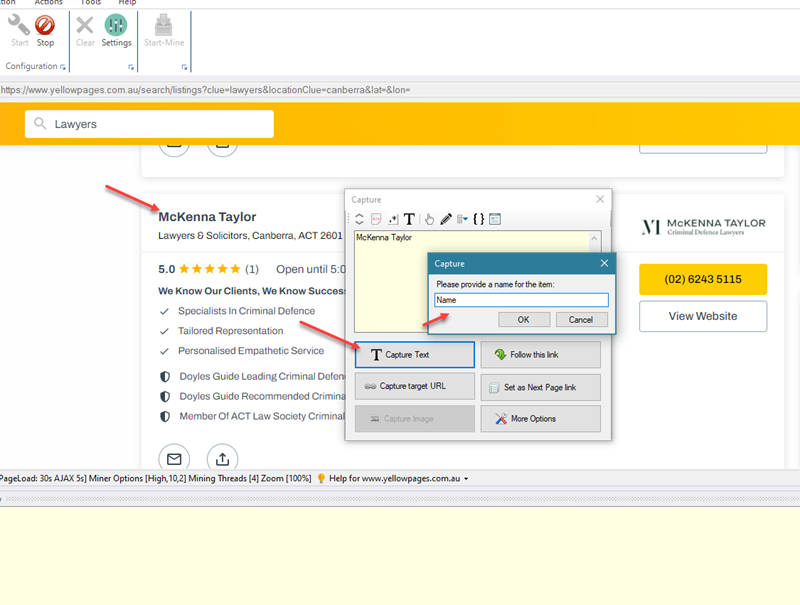
You can now click and select any required data item from the page for extraction. To scrape the name of the listing, click on the name of the first non-ad (non sponsored / featured) listing and from the resulting Capture window displayed, select the Capture Text option.
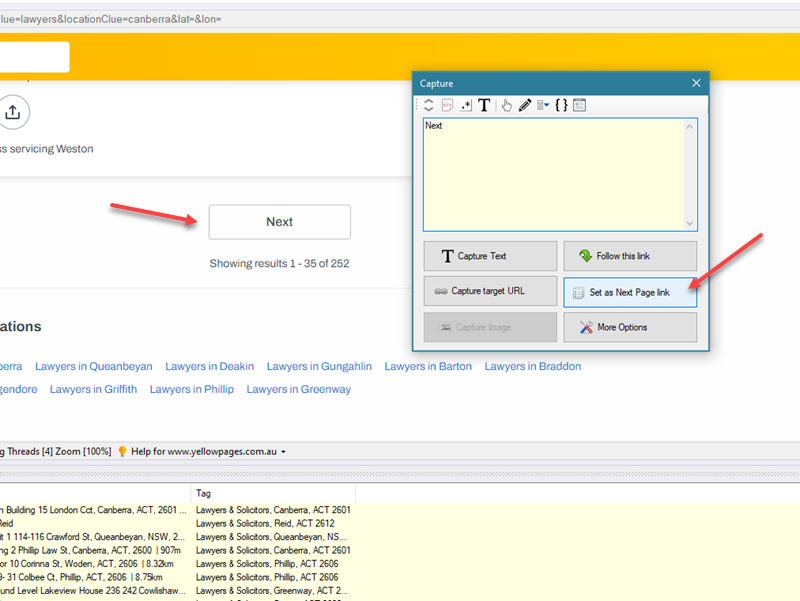
Details like email, phone number etc. can be selected from the listing details page which is loaded by clicking and following the link of the listing. Before following links, you will need to teach WebHarvy how to load and scrape data from multiple pages (pagination). For this scroll down to the bottom of the page and click on the Next link which loads the next page. Select the Set as Next Page link option from the resulting Capture window.
Now you can follow the link of the first listing to load the details page from where additional data like phone number, email address etc. can be selected. Click on the title link of the first listing and select the Follow this link option from the resulting Capture window.
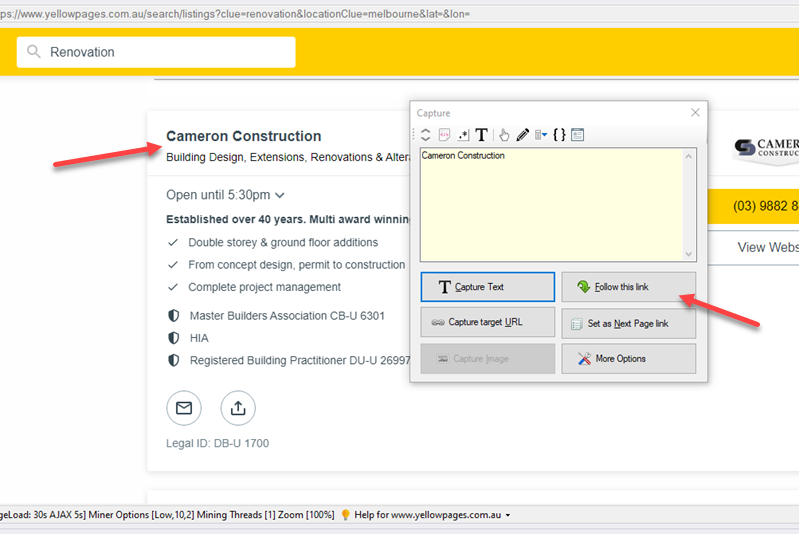
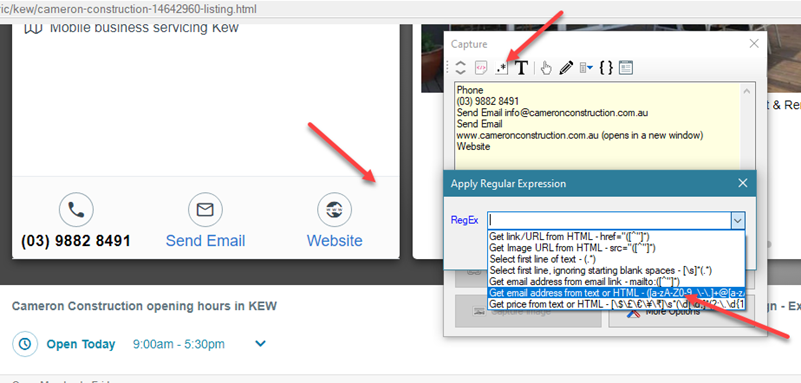
Wait for the listing details page to load. Once loaded, you can directly click and select the address and phone number texts using the 'Capture Text' option in Capture window.
To select email address, place the mouse pointer such that the entire row of phone number, email and website is highlighted and then click. From the resulting Capture window select the Apply Regular Expression option and use the RegEx string corresponding to scraping emails.
Once you have selected all required data, you can stop configuration by clicking on the Stop button in the top menu. You may now optionally save the configuration so that it can be run later. Saved configurations can also be edited in case you wish to add or remove data fields from the configuration. Click the Start Mine button to start mining data using the configuration. In the resulting Miner window displayed, click the Start button and WebHarvy will start to scrape data from the website for which we created the configuration.
Scraped data can be saved to a file or exported to a database. WebHarvy also allows you to schedule web scraping tasks so that they run without user intervention and fetch the latest data to a file or database.
Video Demonstration
The following video shows how WebHarvy can be used to scrape details like name, website, email, phone number and address from yellowpages.com.au listings.
Try WebHarvy
We recommend that you try the free evaluation version of WebHarvy available for download.
Getting started with web scraping using WebHarvy
Need Help?
If you have any questions or need assistance in setting up WebHarvy for Yellow Pages scraping, please do not hesitate to contact our technical support team by providing details regarding your requirement or problem faced.