What is Yellow Pages Scraping?
Yellow Pages Scraping is the process of automatically extracting business contact details and other data from Yellow Pages listings. Based on location there are various flavors of Yellow Pages websites.
- www.yellowpages.com (US)
- www.yellowpages.com.au (Australia)
- www.yellow.co.nz (New Zealand)
- www.yellowpages.ca (Canada)
- www.yellowpages.com.sg (Singapore)
- www.yell.com (UK)
- www.paginasamarillas.es (Spanish)
- www.pagesjaunes.fr (France)
The following are the list of data which can be scraped from yellow pages listings.
- 1. Business Name
- 2. Street Address
- 3. State, Postal Code
- 4. Phone Number
- 5. Map Coordinates / Business Location
- 6. Email
- 7. Website
- 8. Business Description
- 9. Rating and Reviews
- 10. Opening hours
Which software can be used to scrape Yellow Pages?
To scrape data from Yellow Pages, you can either use a software built specifically for the purpose (like YellaBot, YPSpider etc.) or use a general-purpose web scraping software (like WebHarvy, ParseHub, OctoParse etc.). Software which are built exclusively for Yellow Pages scraping are called Yellow Pages Scrapers.
The advantage of using a YP specific software is that it will be easy to use, but with limited flexibility. If you use a visual web scraper like WebHarvy you can use it to scrape data from any type of Yellow Pages website (as well as from any other website) with a lot of flexibility in selecting the required data and automating / scheduling the process.
How to scrape data from Yellow Pages?
We will now see how WebHarvy can be used to easily scrape data from Yellow Pages listings. First, you will need to download and install WebHarvy in your computer.
Once installed, you can open WebHarvy and load any website within its configuration browser. For our requirement, we will load the Yellow Pages listings page from which we need to scrape data.
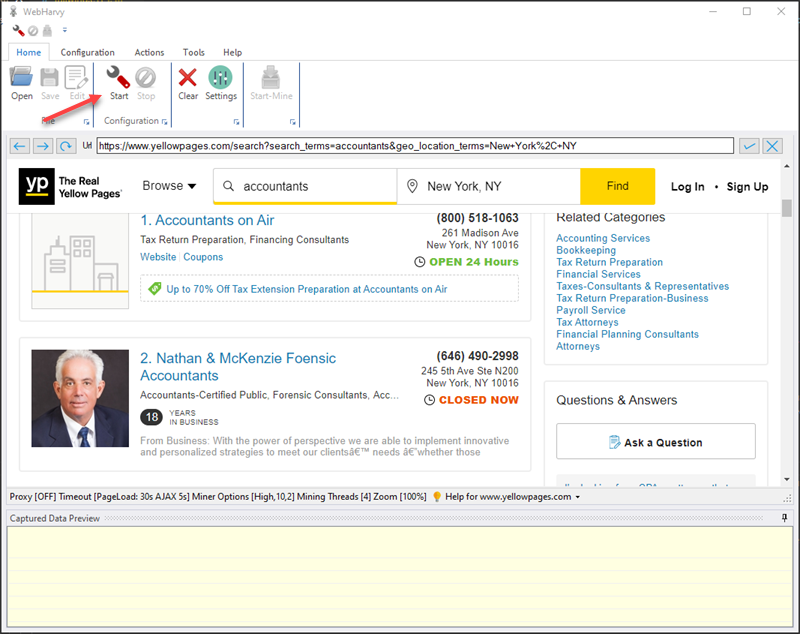
In the above example we have loaded www.yellowpages.com and searched for accountants in New York. To select the data which we require to scrape from this listing, click on the Start Configuration button.
In configuration mode, as you hover the mouse pointer over various items (text or image) displayed on the page, they will be highlighted in yellow. Just click over the text which you need to scrape. WebHarvy will display a Capture window.
One thing to note here is that, it is always recommended to skip over the sponsored listings (ads) displayed at the top of the page and select data from the first non-ad listing.
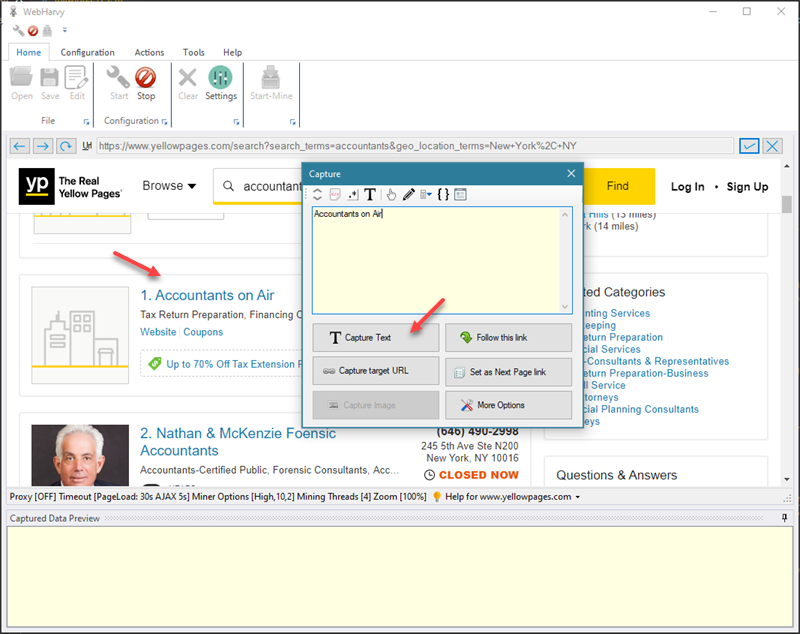
The capture window has various options. Click on the 'Capture Text' option to capture the text of selected item. In the next window, you can provide a name for the selected data field. Then, click the OK button. WebHarvy will automatically parse and select similar items from subsequent listings and display them in the Captured Data Preview pane. By following this method, you can select details like name, address, phone number etc. from the page.
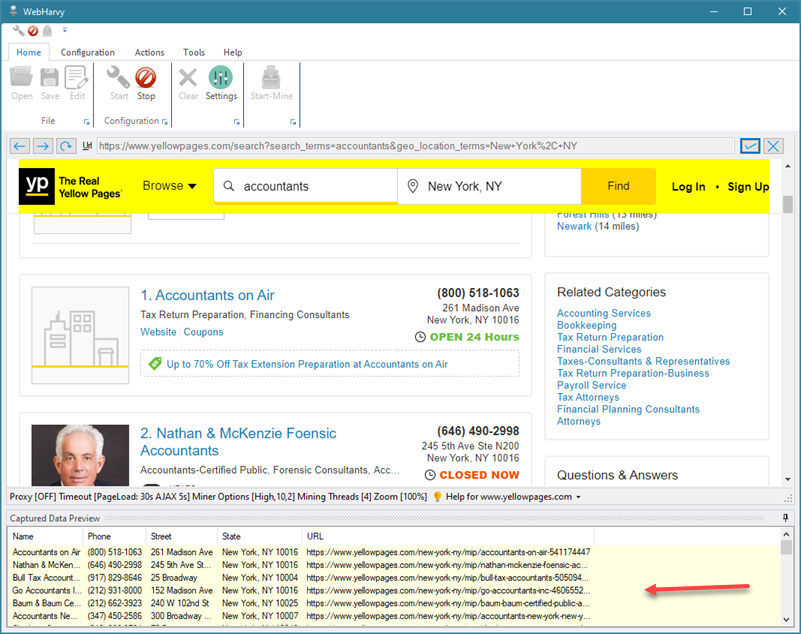
To scrape the data which we have selected from multiple pages of listings, scroll down to the bottom of the page and click on the link to load the next page. From the Capture window displayed, select the Set as Next Page link option.
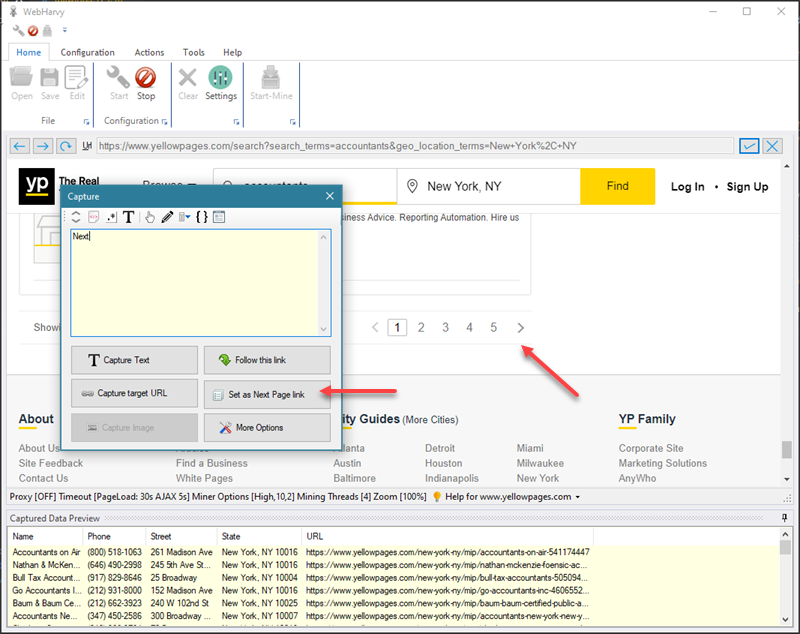
You can also configure WebHarvy to follow each listing link to load its details page and scrape additional data.
Once all required data has been selected from the page, click the stop configuration button in the top menu. You can now optionally save the configuration.
To start mining data using the configuration which we created, click on the 'Start Mine' button. This will bring up the Miner window. Click the Start button to start mining.
WebHarvy will load the starting page for which we created the configuration and start scraping data from it. It will then load subsequent listing pages and repeat the same process. As mining proceeds, the scraped data will start appearing in the Miner window data table.
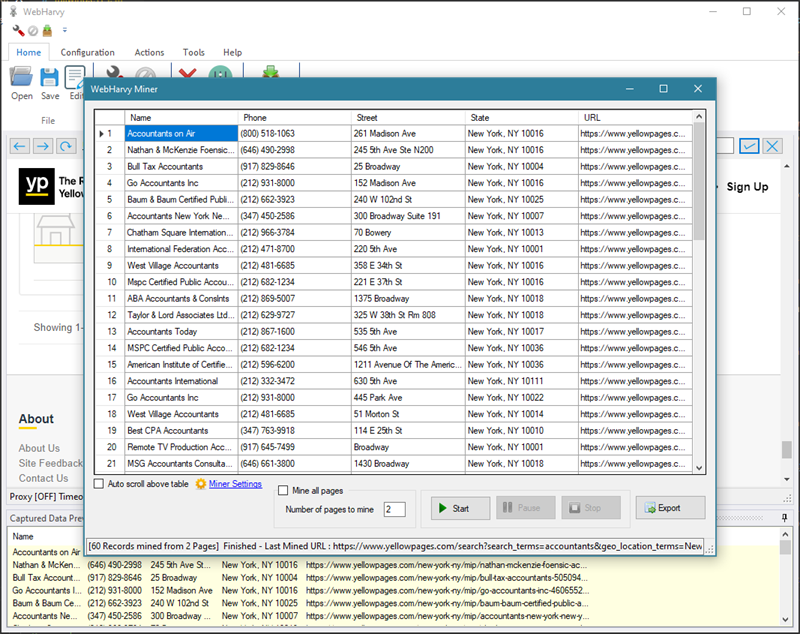
Once mining is finished, you can save the mined data to a file or database. Various file formats (XML, CSV, Excel, TSV, JSON) and databases (MS SQL, My SQL, Oracle) are supported.
Yellow Pages Scraping Video
The following video shows in detail how WebHarvy can be configured to scrape data from Yellow Pages (www.yellowpages.com) listings.
Try WebHarvy
WebHarvy is free to try. We recommend that you download and try the free evaluation version of WebHarvy. To get started please refer this guide.
Have Questions?
If you have any questions regarding WebHarvy or need assistance in configuring WebHarvy, please do not hesitate to contact our technical support team.
Related Articles