Web scraping can be used to download property listing data displayed by various real estate platforms like Trulia, Zillow etc. The dynamic web data displayed by these websites can be transformed into structured, downloadable tables that can be saved in various file formats or in a database. Real estate companies and agents can use this data to make informed investment decisions as well as to better serve their customers.
How to scrape property data from real estate websites?
You need to use a web scraping software to extract data displayed by real estate websites. There are several types of web scraping software. WebHarvy is a visual web scraping software using which data can be easily extracted from any real estate website including Trulia, Zillow, Realtor.com etc. You can download and install WebHarvy locally in your computer. WebHarvy's point and click interface allows you to easily select data from websites via simple mouse clicks.
If you are a developer (or can hire one), you can build your own custom web scraping script or software to extract the required data from real estate websites. For this, you can use programming languages like Python, JavaScript, or PHP along with libraries like BeautifulSoup, Scrapy, or Puppeteer. However, this requires programming knowledge and may take more time compared to using a visual web scraping tool like WebHarvy.
Scraping Trulia using WebHarvy
WebHarvy is a no-code, web scraping tool using which you can scrape data from any website. To use WebHarvy, you should first download and install it in your computer.
Once installation is complete, launch WebHarvy and load the page from which you need to scrape data. WebHarvy contains a built-in browser using which you can load and navigate web pages, just like a normal web browser.
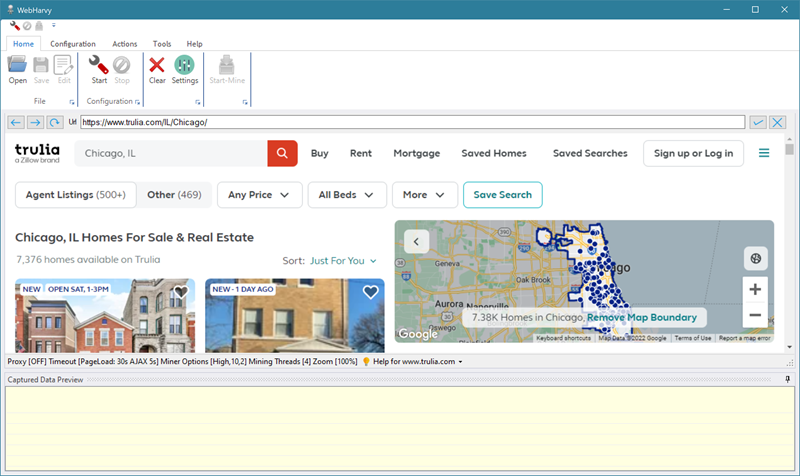
The image above shows Trulia property listings page for Chicago loaded within WebHarvy.
Selecting Property Data to Scrape
Once you have loaded the page from which you need to scrape data, click on the Start button in the Configuration section of the Home menu. You can then click and select any data item from the page for extraction. For example, click on the address of the first property. WebHarvy will show a Capture window with various options. Select the Capture Text option to scrape the text of the item. When you click OK, WebHarvy will automatically parse the entire page and select addresses of all properties listed on the page. The selected data is displayed in the Captured Data Preview pane.
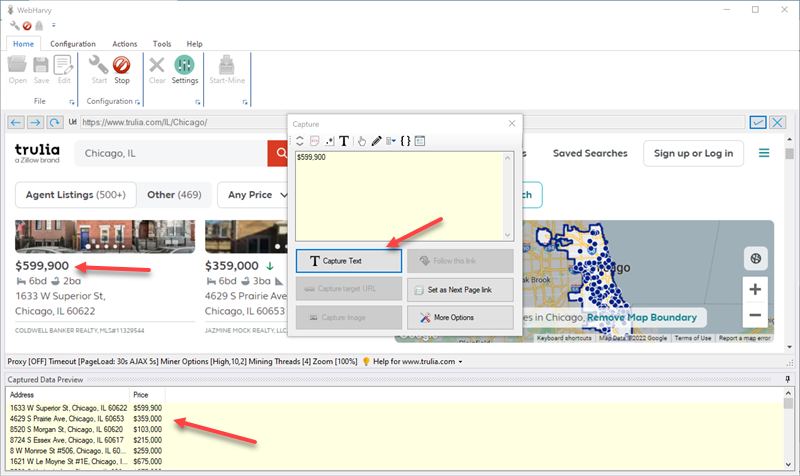
You can select details like address, price, beds/baths/area, thumbnail image etc. by following this method.
Scraping property data from multiple pages
Since the property listings for a location span across multiple pages, we should teach WebHarvy how to load the subsequent pages. For this, scroll down to the bottom of the page and click on the link to load the next page or the direct link to load page number 2.
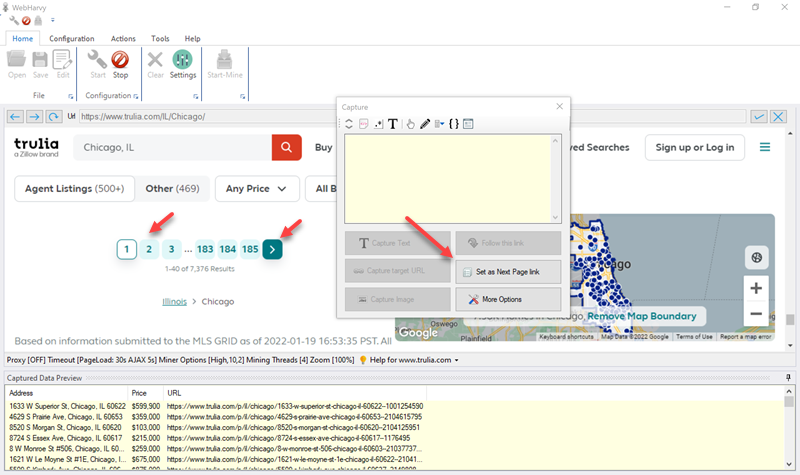
From the resulting Capture window, select the Set as Next Page Link option.
How to load and scrape data from property details pages?
You can also instruct WebHarvy to follow each property link to load the property details page and then scrape data displayed in that page. For this, click on the first property link and select the Follow this link option from the resulting Capture window. This will load the property details page of the first property. Wait for the page to load completely and then you can click and select required data from the page.
The data which you select from the first property details page during configuration will be scraped from all property pages during mining. Whenever possible, it is recommended to use the Capture Following Text method to select the text to scrape, for more accuracy.
Scraping data
Once you have finished selecting all required data, click the Stop button in the Configuration section of Home menu. Then, click on the Start Mine button. In the resulting Miner window, click on the Start button to start scraping data.
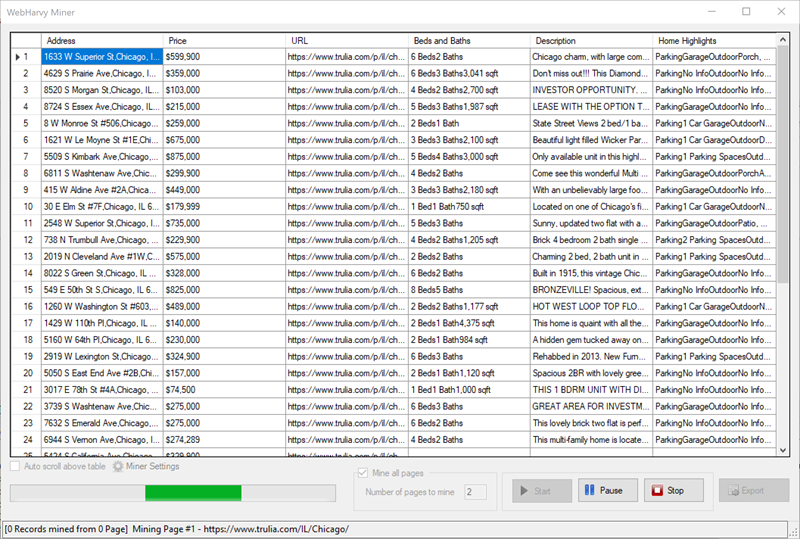
The scraped data can be saved to a file or exported to a database.
Watch the video demonstration
The following video shows how WebHarvy can be configured to scrape property data from Trulia's real estate listings. Codes used in the video can be found in the video description.
Scraping Owner/Agent Contact Name and Phone Number
Video below shows how to scrape the contact name and phone number of the property owner or agent from Trulia's real estate listings.
Try WebHarvy
You can download the free 15 days trial version of WebHarvy and try scraping Trulia property listings.
Need Help? | Have Questions?
In case you need assistance or have any questions, please do not hesitate to contact our technical support.