Data displayed by websites can only be viewed using a web browser. Most websites do not allow you to save or download this data. If you need to save this data, the only option is to manually copy and paste the data - a very tedious job which can take many hours or days to complete. Web Scraping is the technique of automating this process, so that instead of manually copying the data from websites, the Web Scraping software will perform the same task within a fraction of the time.
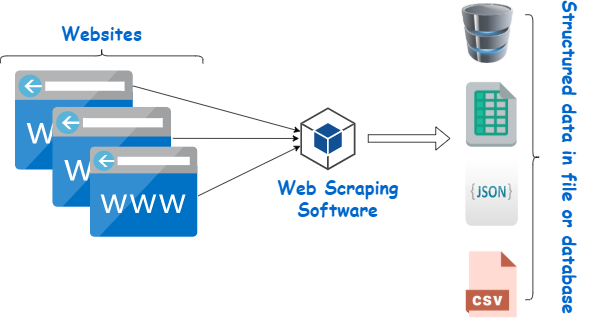
A web scraping software will automatically load, crawl and extract data from multiple pages of websites based on your requirement. It is either custom built for a specific website or one which can be configured to scrape data from any website. With the click of a button, you can easily save the data displayed by websites to a file in your computer.
What is Web Scraping used for?
Web Scraping is used for getting data. Access to relevant data, having methods to analyze it and performing intelligent actions based on analysis can make a huge difference in the success and growth of most businesses in the modern world. Data collection and analysis is important even for government, non-profit and educational institutions.
The following are few of the many uses of Web Scraping:
- 1. In eCommerce, Web Scraping is used for competition price monitoring.
- 2. In Marketing, Web Scraping is used for lead generation, to build phone and email lists for cold outreach.
- 3. In Real Estate, Web Scraping is used to get property and agent/owner contact details.
- 4. Web Scraping is used to collect training and testing data for Machine Learning projects.
Know More about Practical Uses of Web Scraping
Is Web Scraping Legal?
One of the most frequent questions which comes to your mind once you have decided to scrape data is whether the process of web scraping is legal or not. Scraping data which is already available in public domain is legal as long as you use the data ethically. If websites wish to prevent web scraping, they can employ techniques like CAPTCHA forms and IP banning. Web Scraping software can help you scrape data anonymously by routing requests through proxy servers or VPNs, reducing the risk of detection and blocking by websites.
Know more about the legality of Web Scraping
How to scrape data from websites?
1. Using a web scraping software
Web Scraping software falls under 2 categories. First, which can be locally installed in your computer and second, which runs in the cloud (browser based). WebHarvy, OutWit Hub, Visual Web Ripper etc. are examples of web scraping software which can be installed in your computer, whereas import.io, Mozenda, ParseHub, OctoParse etc. are examples of cloud data extraction platforms.
How to choose a web scraping software?
2. By writing code or by hiring a developer
You can hire a developer to build custom data extraction software for your specific requirement. The developer can in-turn make use of web scraping APIs or libraries. For example, apify.com lets you easily get APIs to scrape data from any website. Beautiful Soup is a Python library which helps you parse data out of HTML code behind web pages.
-
How to code a simple web scraper?
-
Various ways to Scrape Data from Websites
How does web scraping software work?
Most web scraping software use a headless (invisible) web browser to load and navigate web pages. The software will load the target page using this browser and then extract the required data. The software can also follow links within the page to scrape additional data. If the website displays data in listings spanned across multiple pages, it handles pagination - by automatically loading the next page and repeating the data extraction process until the last page is reached.
In addition, web scraping software can perform actions like clicking buttons, entering text in input fields, selecting options from dropdown menus and running custom JavaScript code on the page. The extracted data is stored in tabular format and can be saved to a file (excel, json etc.) or database.
Web Scraping Need Not be Hard
The problem with most generic web scraping software is that they are very difficult to master and use. There is a steep learning curve involved. WebHarvy was designed to solve this problem. With a very intuitive, point and click interface, WebHarvy allows you to start scraping data within minutes from any website.
If you are interested in knowing more, we highly recommend that you download and try the FREE 15 days evaluation version of WebHarvy.
What is Web Scraping (Video) ?