
Table of Contents
- What is Puppeteer?
- Uses of Puppeteer
- How to install?
- How to start a browser instance?
- How to load a URL?
- How to navigate/interact with the page?
- How to take screenshots, save page as PDF?
- How to select data from page?
- Headless browser as a service
What is Puppeteer?
Puppeteer (https://developers.google.com/web/tools/puppeteer) is a headless Chrome browser for developers. Puppeteer is made available as a Node library.
Uses of Puppeteer
Puppeteer can be used by developers for browser automation. Developers can create a headless Chrome browser instance using which web pages can be loaded, interacted with and also take screenshots or PDF of loaded pages. Some of the main usages of Puppeteer are for web scraping, browser automation and automated testing.
How to install Puppeteer?
Since Puppeteer is a Node library (requires Node.js installation), it can be installed by running the following command.
$ npm install –save puppeteer
How to start browser instance?
The following code will start a headless (without user interface, invisible) browser instance.
const puppeteer = require(“puppeteer”);
var browser = await puppeteer.launch();
var page = await browser.newPage();
How to load a URL?
To load a URL in the above created browser instance, use the following code.
await page.goto(“https://www.webharvy.com”);
How to select items (elements) from the page?
To select an item/element from the page loaded in puppeteer, you will first need to find it’s CSS selector. You can use Chrome Developer Tools to find the CSS Selector of any element on page. For this, after loading the page within Chrome, right click on the required element and select Inspect.
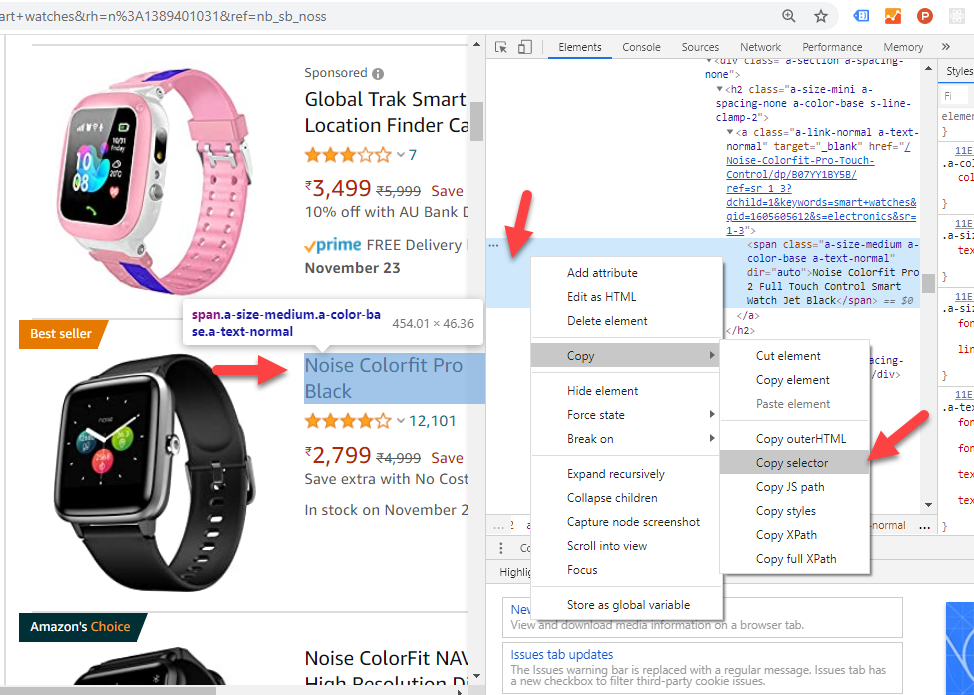
In the resulting Developer Tools window displayed, the HTML Element corresponding to the element which you clicked on page will be selected. Right click on this element and in the resulting menu displayed you will find the Copy submenu within which you should select the Copy selector option. You now have the CSS selector of the element in clipboard.
Example:
#description > yt-formatted-string > span:nth-child(1)
How to interact with page elements?
This selector string can be used within Puppeteer to select/interact with elements. For example to click the above element, assuming it is a link, the following code can be used.
var selector = “#description > yt-formatted-string > span:nth-child(1)”;
page.click(selector);
In addition to click, Puppeteer provides several other page interaction functionality like keyboard input, typing in input fields etc. Refer : https://pptr.dev/#?product=Puppeteer&version=v2.0.0&show=api-class-page
The following code shows how you can select and click a button using Puppeteer once the page is loaded.
var buttonSelector = “#DownloadButton”
await page.evaluate(sel => {
var button = document.querySelector(sel);
Button.click();
}, buttonSelector);
How to get text of page elements?
As shown in the above code samples, we are running JavaScript codes within Puppeteer using page.evaluate function for page interaction. The same can be used to get text of elements from the page.
var reviewSelector = “review > span.cm-title”
var reviewText = await page.evaluate(sel => {
var reviewText = document.querySelector(sel).innerText;
return reviewText;
}, reviewSelector);
As shown above, JavaScript code is executed on page using the page.evaluate method to get text. You may also use the document.querySelectorAll JavaScript HTML DOM method to get data from multiple page elements.
How to take screenshots of page and save page as PDF?
You can take a screenshot of the currently loaded page by using the following code.
await page.screenshot({path: ‘./screenshots/page1.png’});
Or save the page as a PDF using the following code.
await page.pdf({path: ‘./screenshots/page1.pdf’});
Headless browser as a service
Running puppeteer is a resource intensive process. If you need to run several headless browser instances the memory and processor requirements will be high, and scaling them won’t be easy. To facilitate this services like https://www.browserless.io/ can be used which offers headless browsers as a service.