
Scraping product data from Conrad.de, a leading electronics retailer, can provide valuable insights for market research, competitive analysis, and inventory management. Using WebHarvy, a visual point-and-click web scraping tool, makes this process easy and efficient, allowing you to easily extract detailed product information without needing any coding skills. This guide will show you how to use WebHarvy to automate data collection from Conrad.de, saving time and enhancing your data-driven strategies.
Step 1: Install and Launch WebHarvy
Download and install the WebHarvy software from our website. Once installed, launch the application to get started with the scraping process.
Step 2: Load the website and start configuration
Load the page from which you wish to scrape data within WebHarvy’s browser and start configuration.
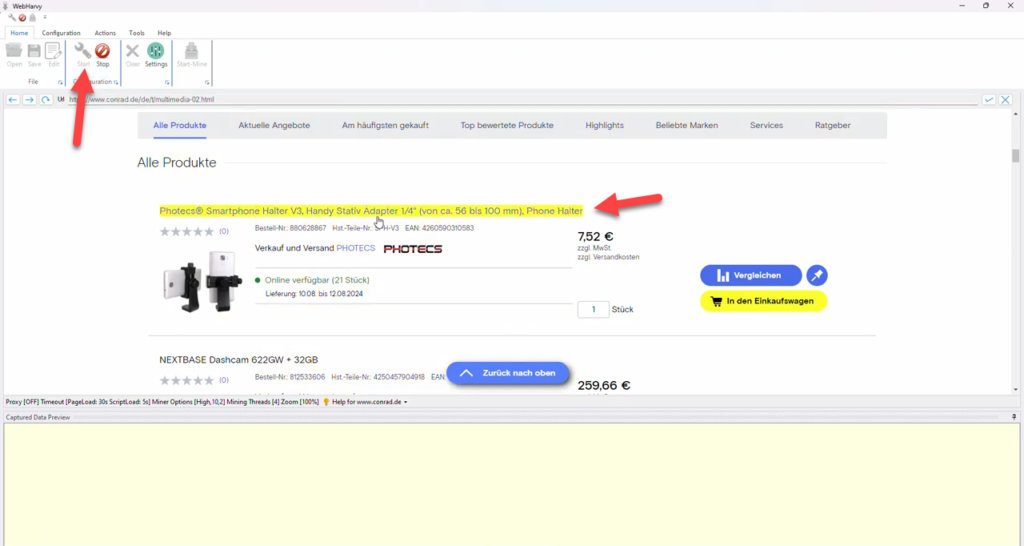
Step 3: Configure Pagination
To scrape product data from multiple pages of product data you need to configure pagination. Click on the title of the first product and select More Options > Scroll List from the resulting Capture window. When the page scrolls down to the bottom, click on the link to load the next page and set it as the next page link.
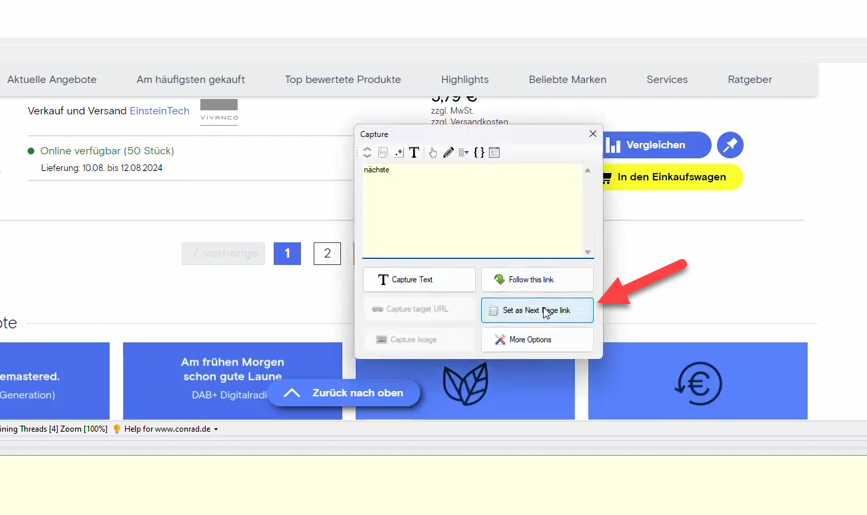
Step 4: Select Data to Scrape
WebHarvy operates in point-and-click mode. Hover over the product data you want to scrape (such as product names, prices, descriptions, and images) and click to select it. WebHarvy will automatically detect similar data across the page and highlight it. Select the Capture Text option from Capture window to select the text of the clicked item (and subsequent items).
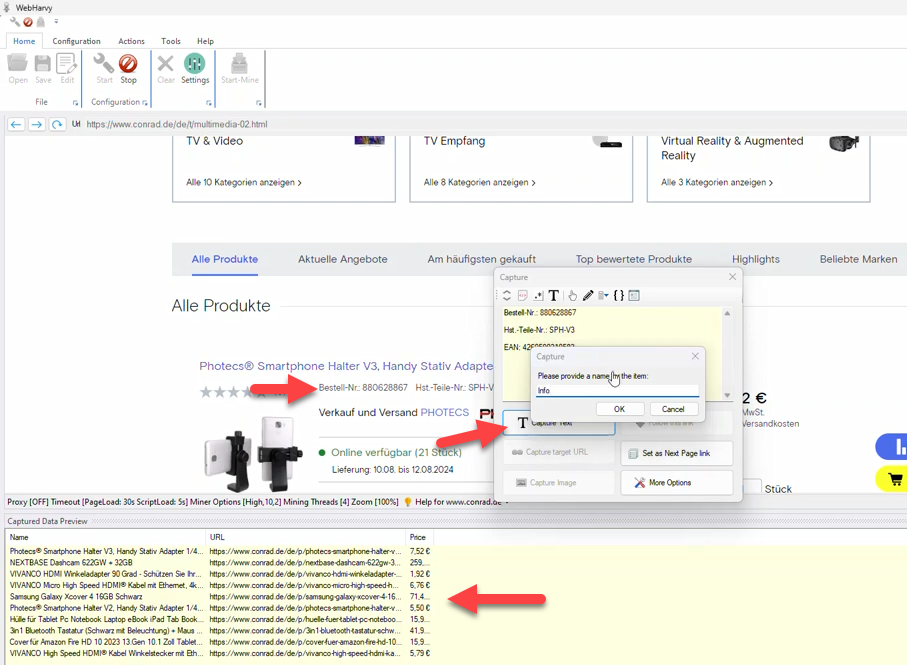
Step 5: Follow product links and scrape additional data
WebHarvy allows you to follow product links and select data from product details pages. For this, click on the title/link fo the first product and select the Follow this link option from the Capture window. Once the product details page is loaded, you can click and select additional data.
Step 6: Stop Configuration and Start Mining
Click on the “Stop Configuration” button to stop the configuration process. You may optionally save the configuration so that it can be run or edited later. Click on the Start Mine button to start mining data.
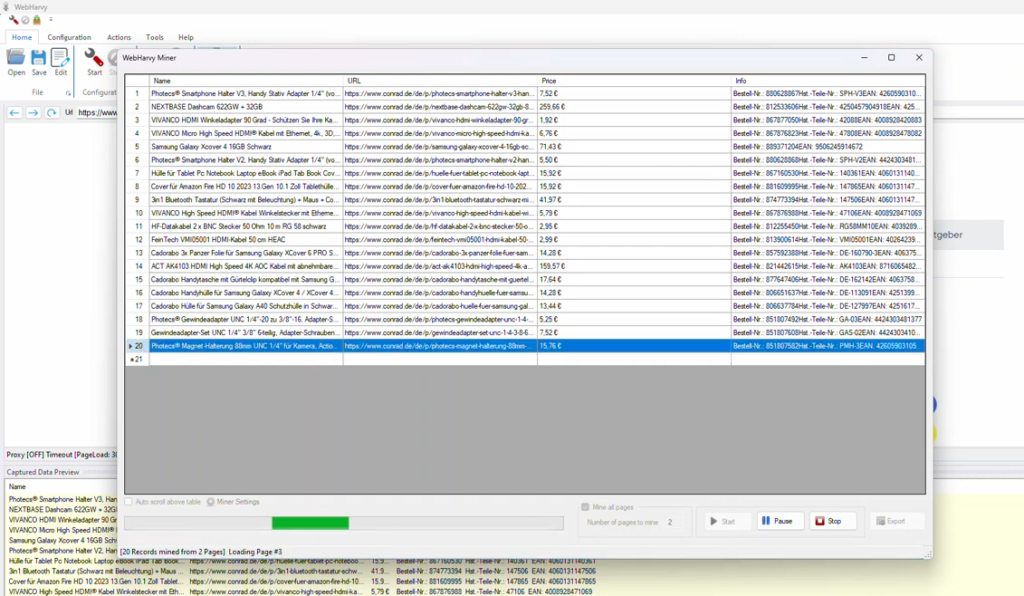
The mined data can be saved to a file or to a database.
Try it!
Download and try the free evaluation version of WebHarvy to see if solves your web scraping requirements. To get started follow this link.