
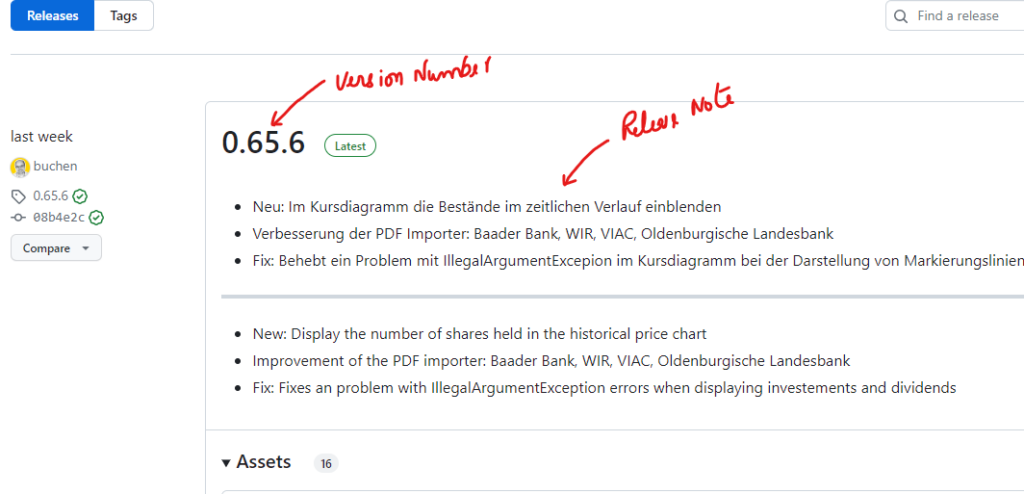
This article demonstrates how WebHarvy can be used to scrape GitHub release notes. With WebHarvy, it is possible to efficiently scrape release details like version numbers and release notes from multiple pages.
WebHarvy is a generic web scraping software which can be used to scrape data from any website.
Steps to follow
The first step is to download and install WebHarvy in your computer, if you have not done so already. Then load the page from which you need to scrape data within WebHarvy’s configuration browser.
Once the page has been loaded, click on the Start button to start configuration. Once in configuration mode, you can click and select any data item (text or image) which you wish to scrape.
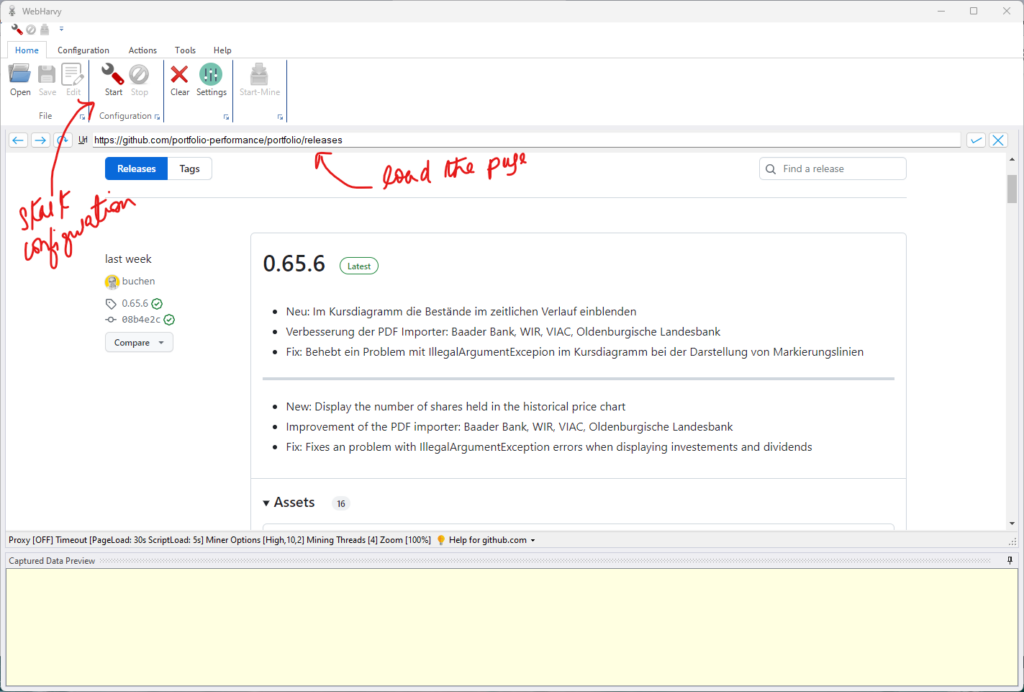
Clicking on any data item on page will bring up a Capture window with various options. Select the Capture Text option to select the text of the clicked item. Details like version number and release note text can be selected for scraping in this manner.
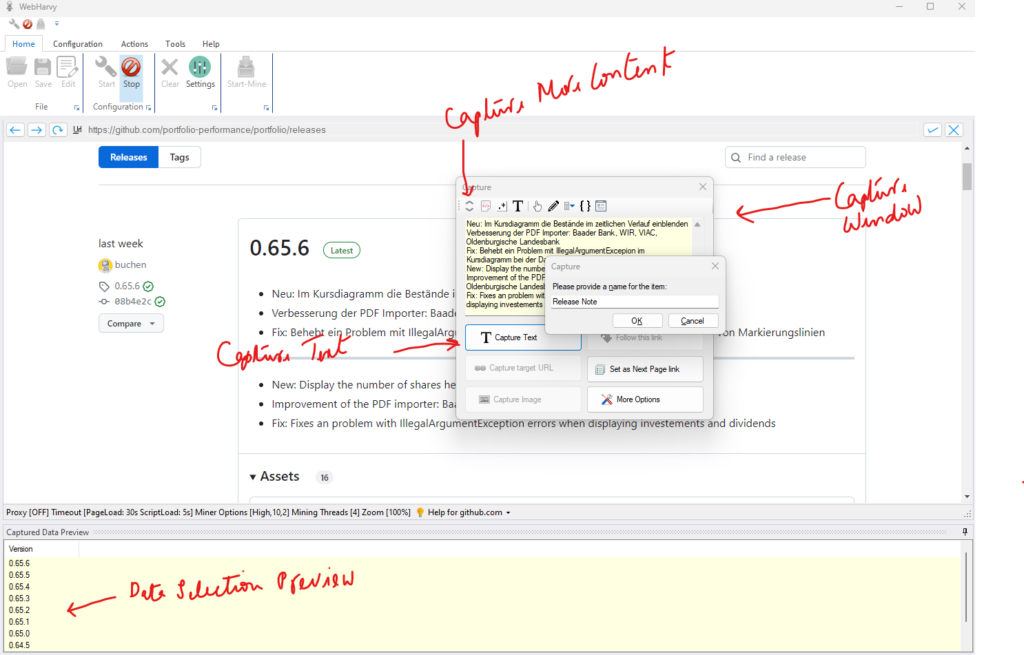
While selecting release notes, if the entire block of text is not selected, you can apply Capture More Content option multiple times till the desired portion is selected.
To configure pagination, that is to teach WebHarvy how to scrape data from multiple pages, scroll down to the bottom of the page and click on the link to load the next page (you may either click on the ‘next’ link or direct link to load page number 2). Then from the resulting Capture window, select the Set as Next Page link option.
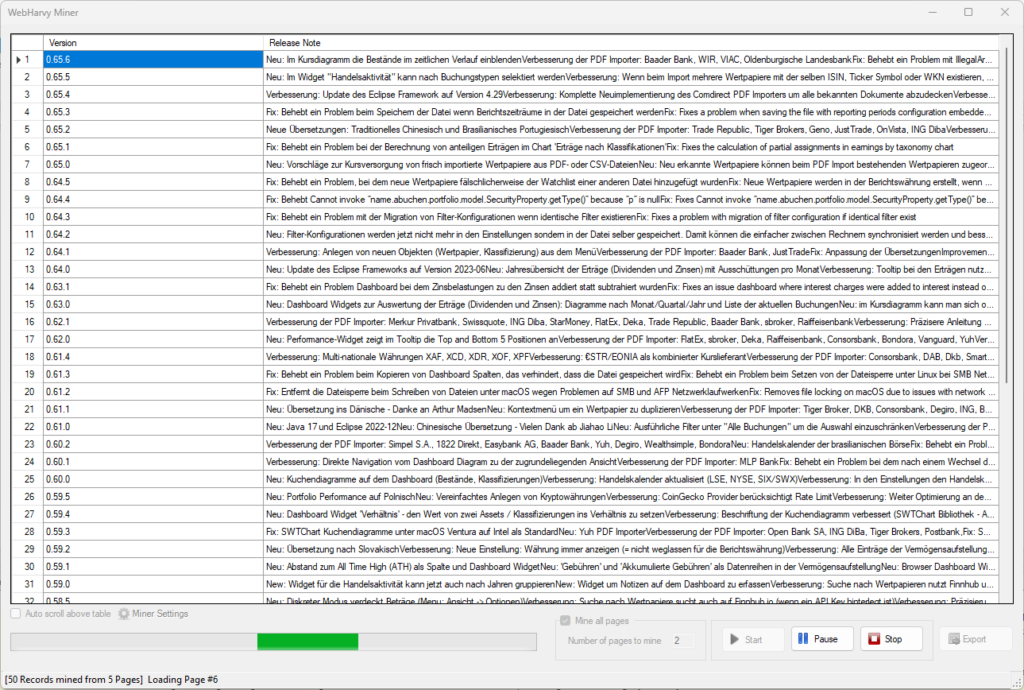
Once all data has been selected, Stop Configuration and Start Mine.
Try WebHarvy
You may download and try the 15 days free evaluation version of WebHarvy by visiting the following link. If you have any questions, please feel free to reach out to our support.