

In this article we will learn how to scrape Crunchbase company data without writing any code, using WebHarvy – a visual point and click web scraping software. Company details like name, address, email address, website etc. can be easily scraped from crunchbase.com using WebHarvy.
Advantages of scraping Crunchbase
Crunchbase is a platform which provides business information related to companies ranging from startups to Fortune 100 companies. Crunchbase has over 60 million users who use it for prospecting, sales intelligence, data augmentation and lead qualification. Crunchbase’s main competitors are ZoomInfo and LinkedIn Sales Navigator. Data scraped from Crunchbase can be used for powering business intelligence and market analysis.
How to scrape Crunchbase?
Step 1: Install WebHarvy
Download and install WebHarvy in your computer. WebHarvy is a visual web scraping software which allows you to select the data which you need to scrape via an easy to use point-and-click user interface. Being a generic web scraping software, WebHarvy can be used to scrape data from any website.
Step 2: Open Crunchbase.com within WebHarvy
Open WebHarvy and load the Crunchbase website. Login using your account. WebHarvy contains a built in browser (based on Chrome) using which you can load and navigate web pages, like a normal browser. After logging into Crunchbase, search and navigate to the company data listings page from which you need to scrape data.
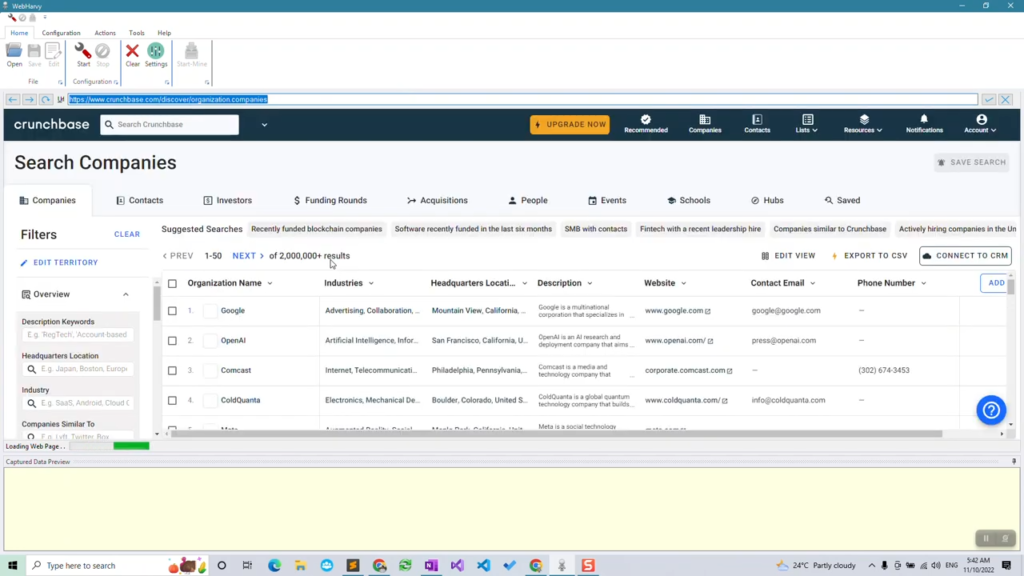
Step 3: Start configuration & select the data required to be scraped
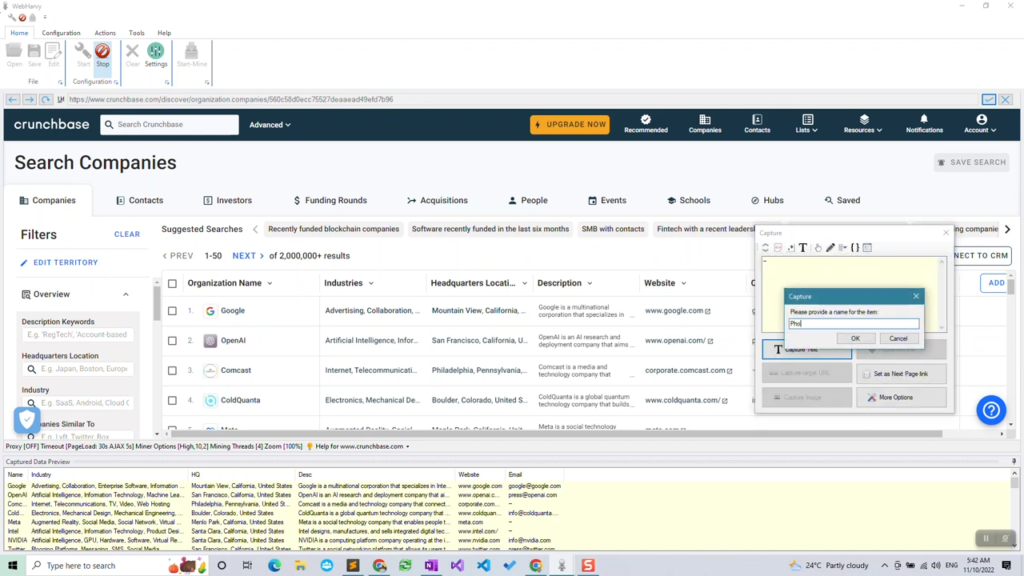
Start configuration by clicking the Start button in the Configuration menu pane. Now you can click and select any data item displayed on page for extraction. Clicking any area of the page will bring up a Capture window with various options. Select the Capture Text option to scrape the text of the selected area.
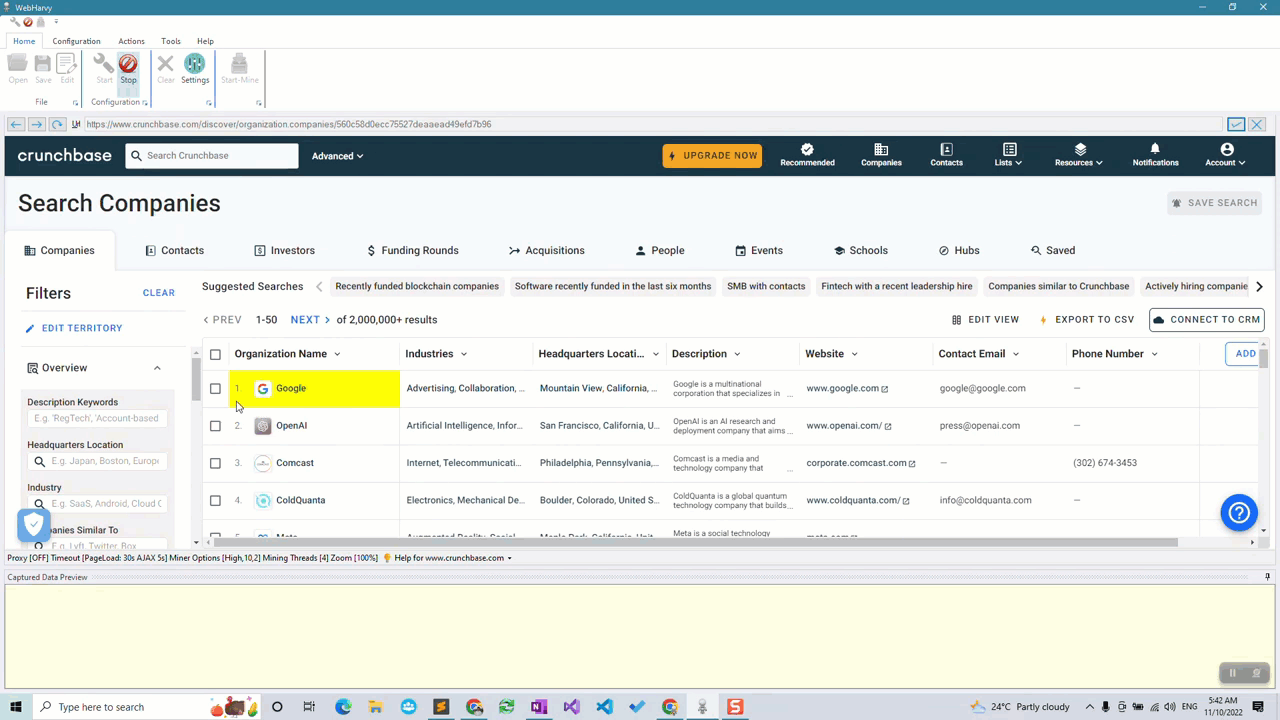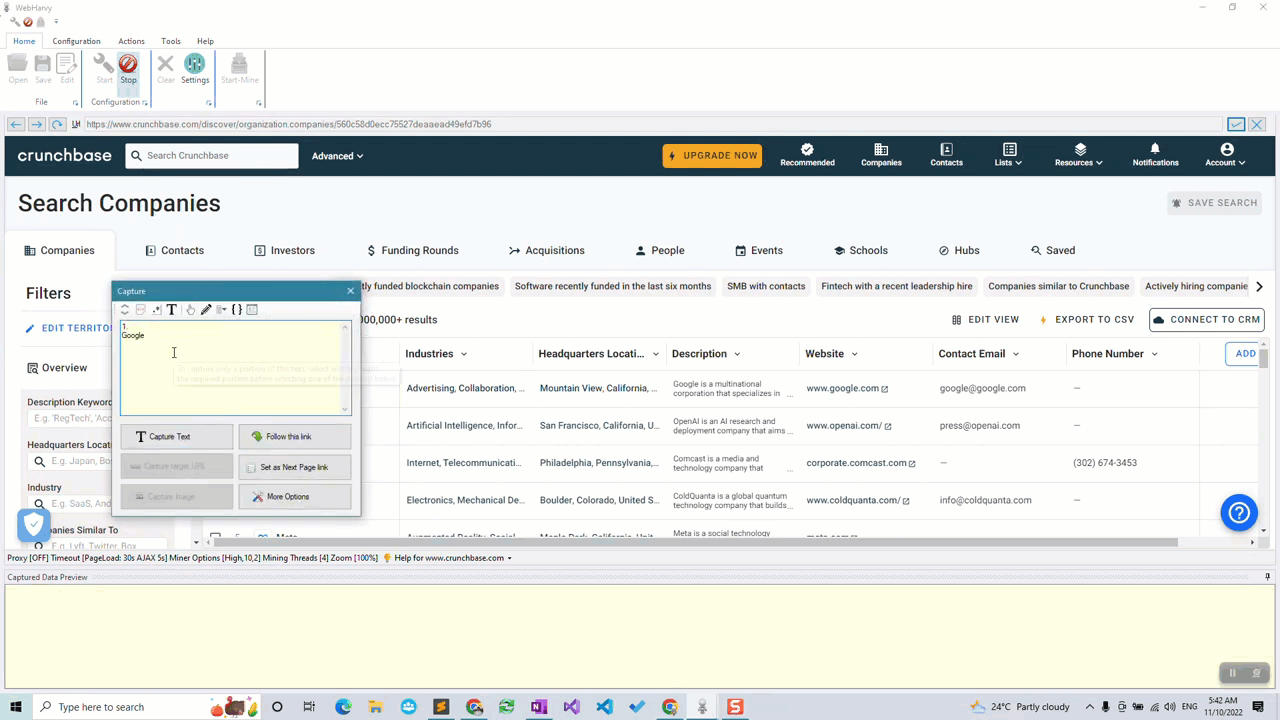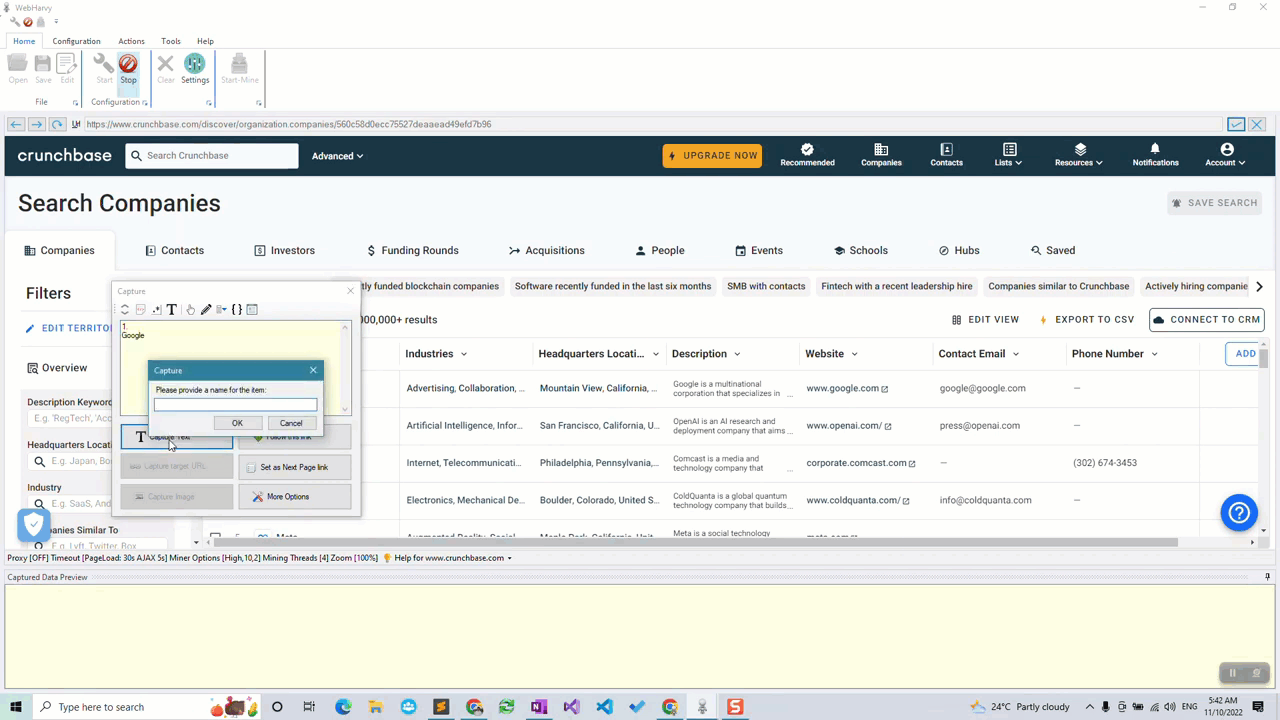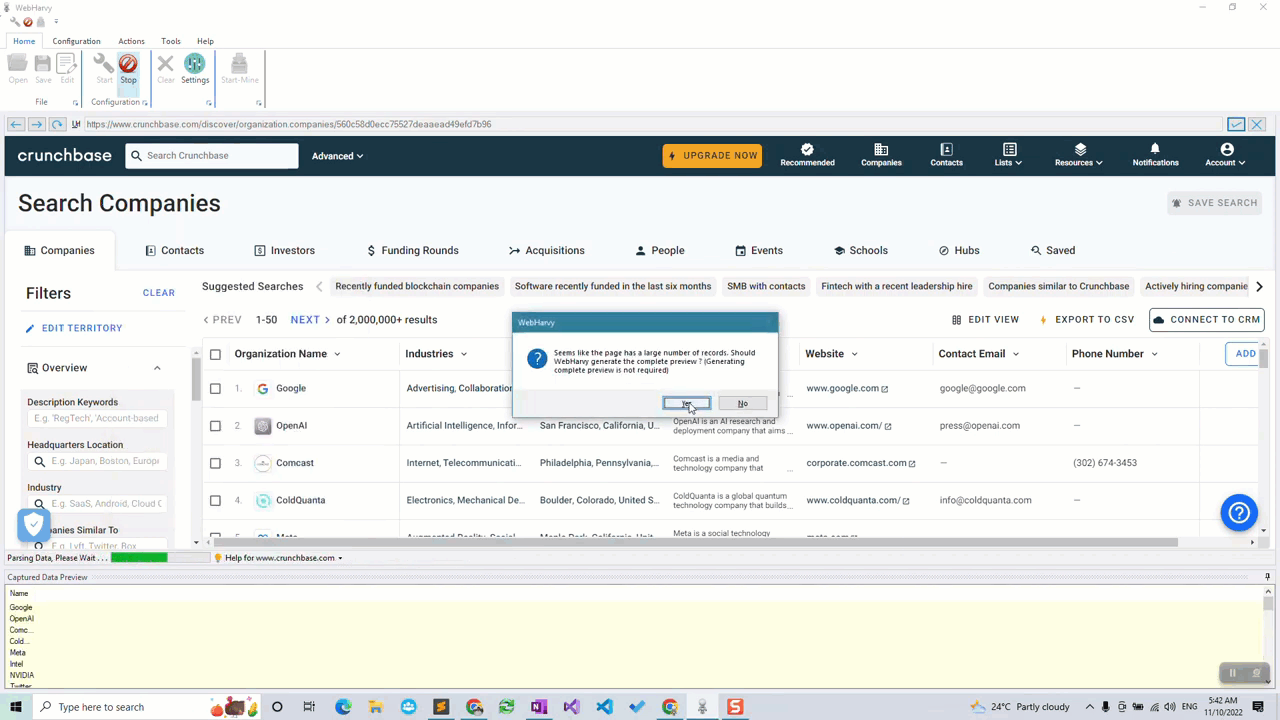
You can click and select details like company name, industry, location, description, website, email, phone number etc. by following the above method.
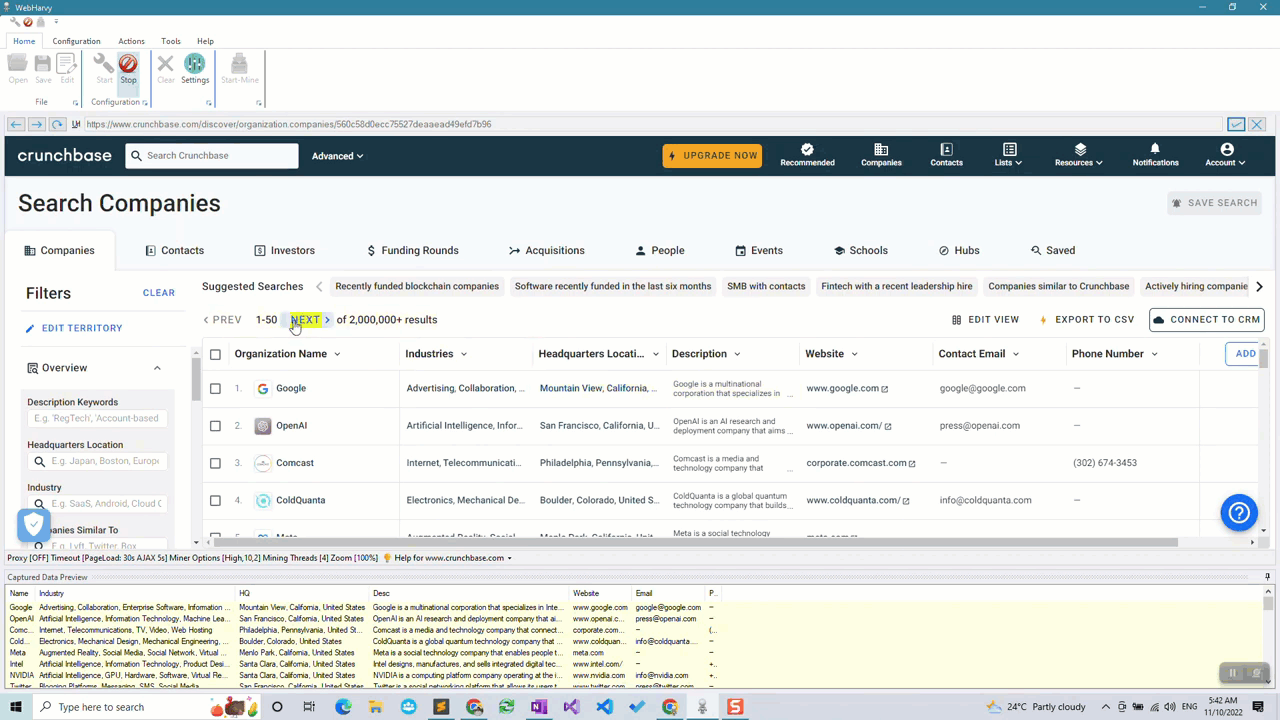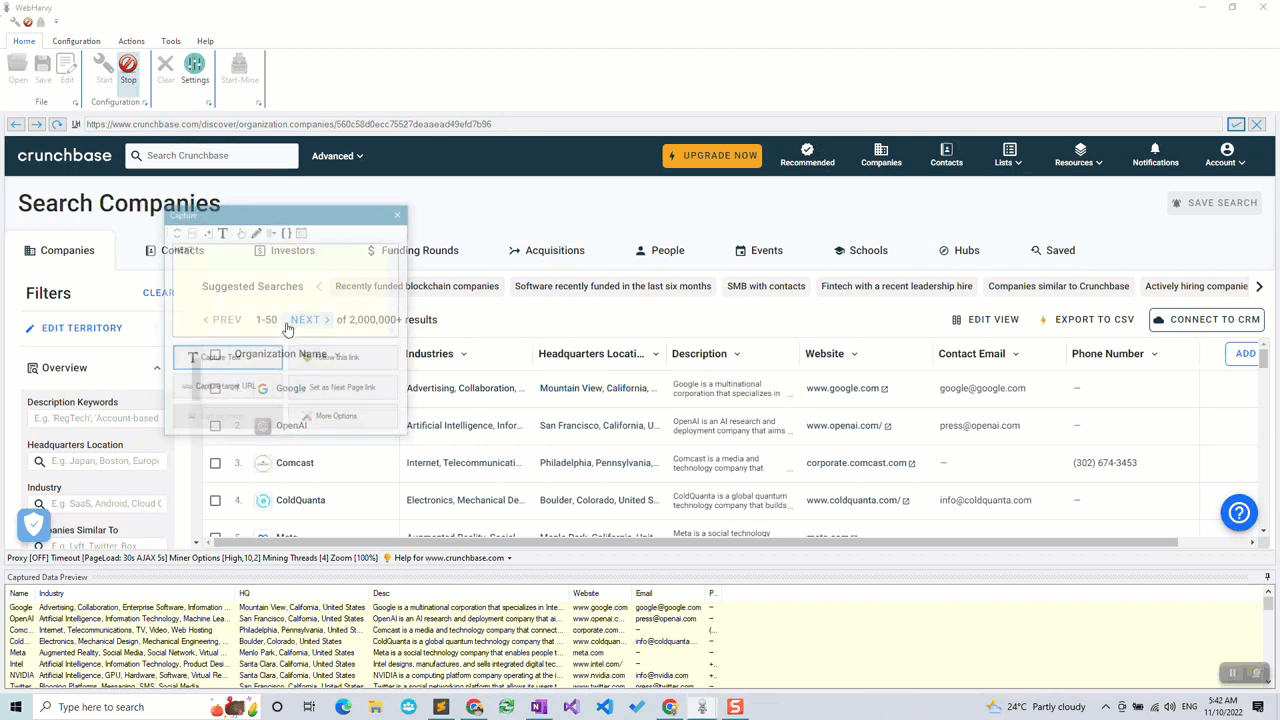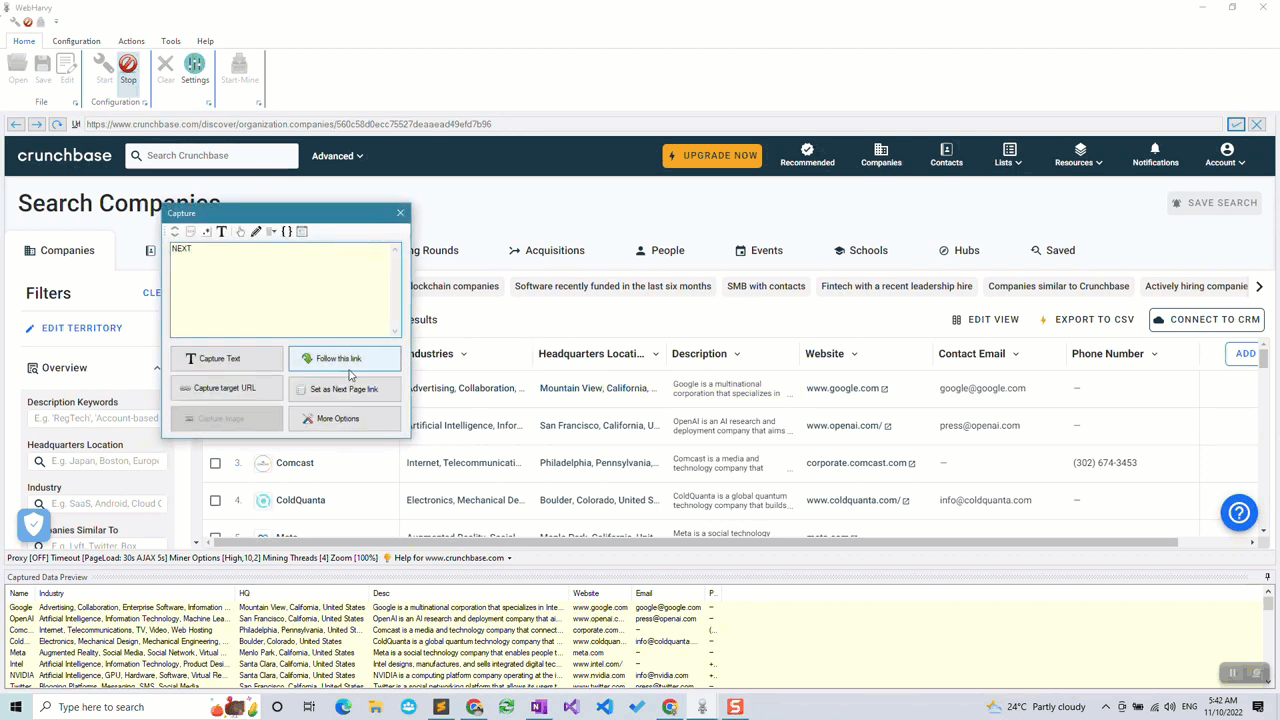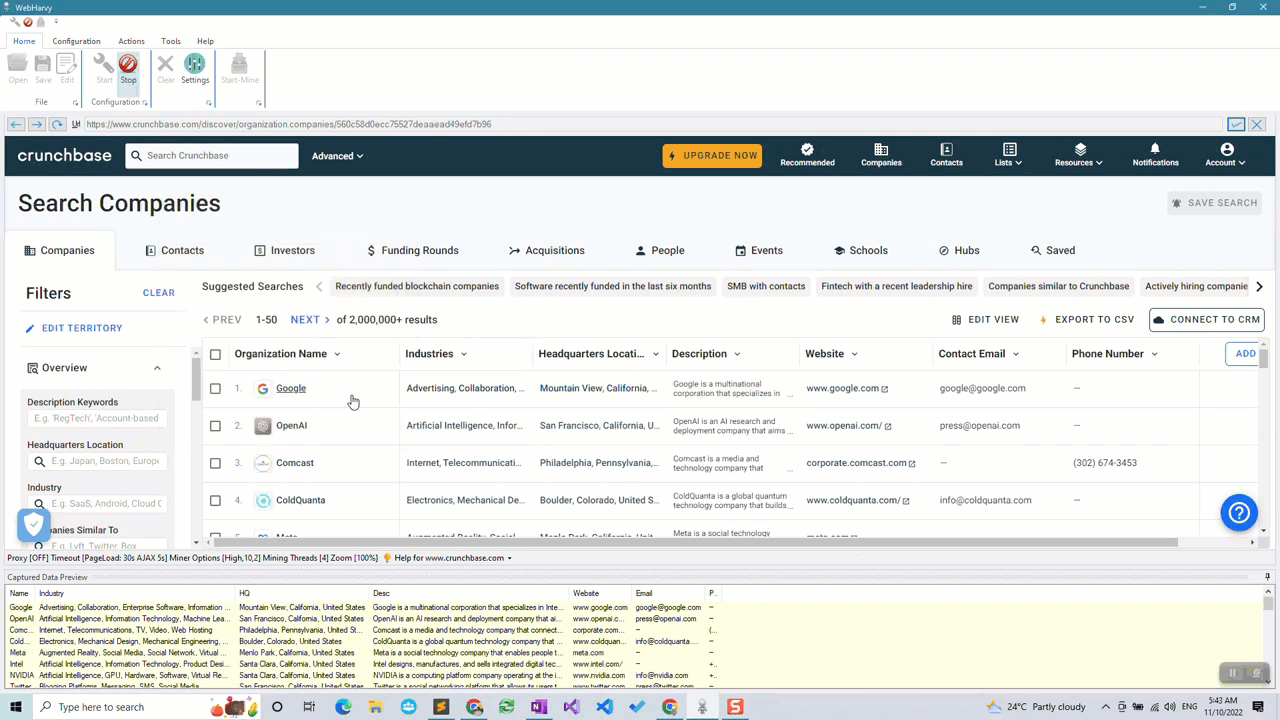
Step 4: Configure pagination
Crunchbase will display millions of rows of company data for your searches and they will be displayed over multiple pages which can be loaded by clicking the NEXT button at the top of the listings. To scrape data from these multiple pages you will have to teach WebHarvy how to load them.
For this, click on the NEXT link and select the Set as Next Page Link option from the resulting Capture window.
Step 5: Stop Configuation
Click the Stop button in the Configuration menu pane to stop configuration. Now you can optionally save the configuration so that it can be run later or edited to make changes.
Step 6: Start Mining
Click the Start Mine button to open the Miner window and start mining data. Click the Start button to start mining. WebHarvy will start scraping data based on the configuration which you created and the data extracted will start to appear in the Miner window’s data table.
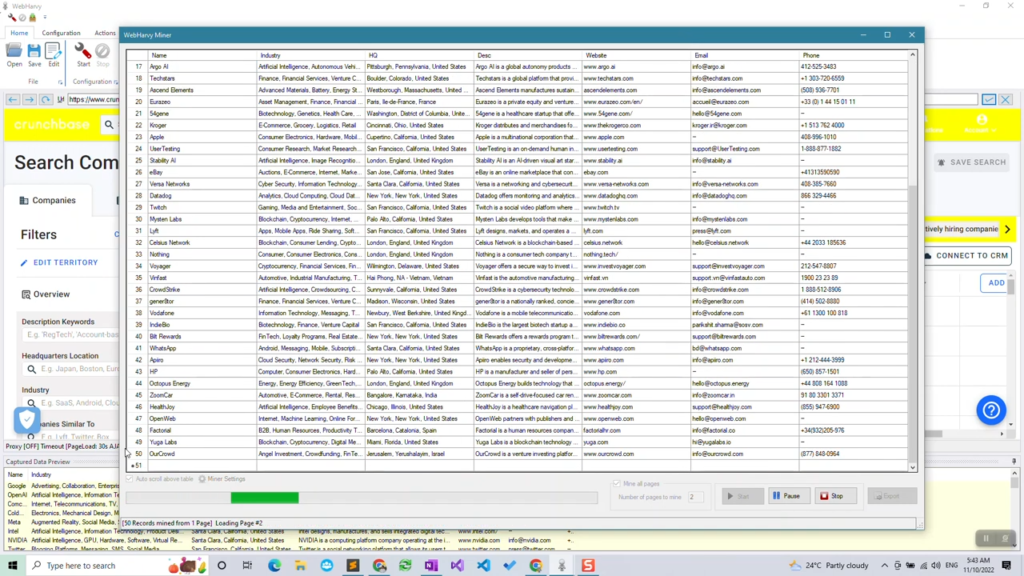
Step 7: Save mined data
Once mining is complete, the data scraped can be saved to a file or database. WebHarvy allows you to save the scraped data in a variety of file formats (including CSV, JSON, Excel etc.) and databases.
Watch Video : Scraping Crunchbase
Video below shows in detail how you can use WebHarvy to scrape data from Crunchbase company listings.
Have questions? Need Support?
If you are new to WebHarvy and web scraping we highly recommend that you refer our getting started guide. If you have any questions or need assistance in configuring WebHarvy please reach out to our technical support team.