
Using WebHarvy’s visual point-and-click user interface you can easily scrape Jooble job listings data. Job details like title, role/position, application link, job description etc. can be easily scraped using WebHarvy.
WebHarvy also supports scraping data from other job listing websites like Indeed, Dice, Monster, Google Jobs etc.
Watch Video
The following video shows how WebHarvy can be used to scrape job details from Jooble job listings.
Steps to scrape Jooble job listings data
Step 1 : Install WebHarvy
Download and install WebHarvy in your computer.
Step 2 : Load the page from which you need to scrape data
Open WebHarvy and load Jooble website. Navigate to (search) the job results page from which you need to scrape data.
Step 3 : Start Configuration
Once you have loaded the page from which data is to be extracted, click the Start button in the Configuration pane.
Step 4 : Select data from the listings page
Click and select the data which you need to scrape. When you click over any text or image displayed in a web page, WebHarvy will display a Capture window with various options. Select the Capture Text option to scrape the text of the clicked item. Details like job title, URL etc. can be selected from the listings page by following this method.
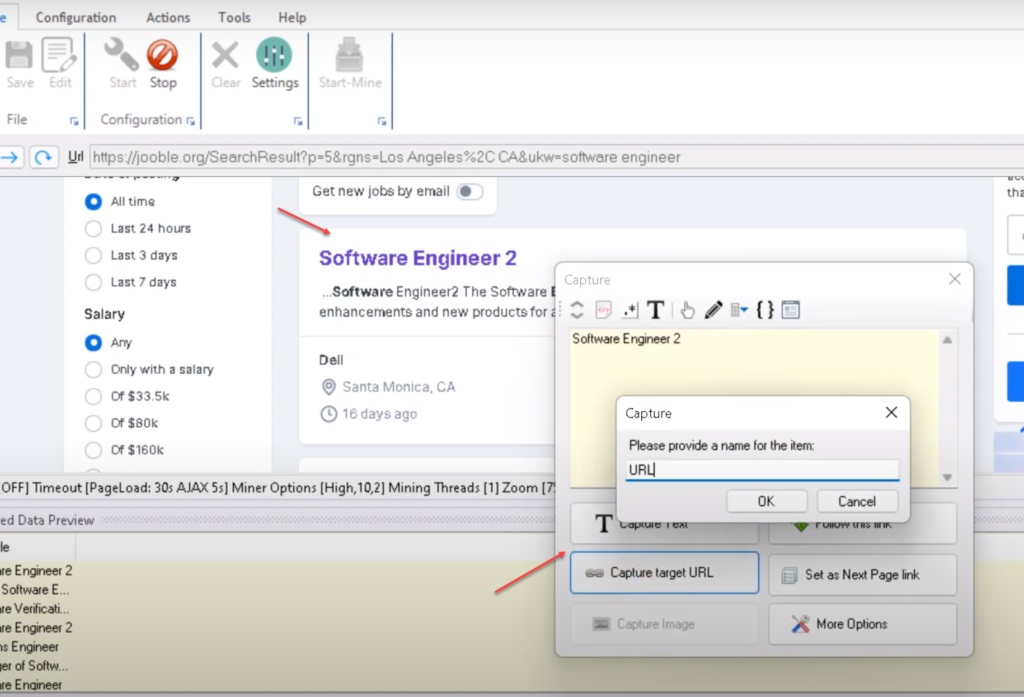
Step 5 : Configure Pagination
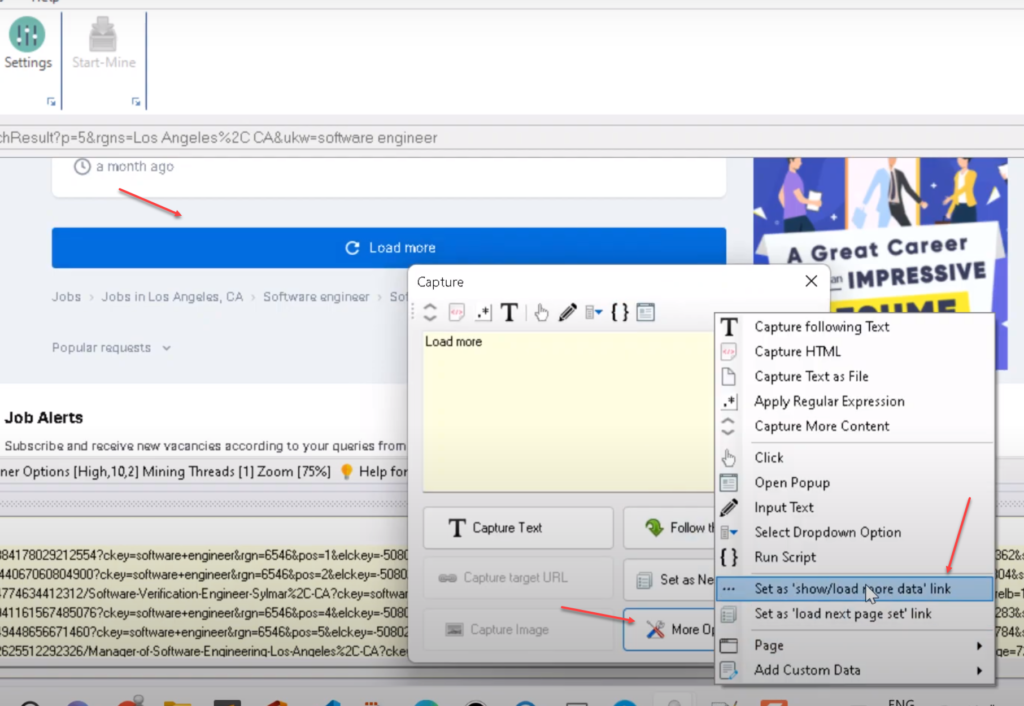
Scroll down to the bottom of the page and click on the ‘Load More’ link/button and select More Options > Set as ‘show/load more data’ link from the Capture window displayed. During mining, WebHarvy will automatically load multiple pages of listings and scrape data from all of them as per the configuration which we create.
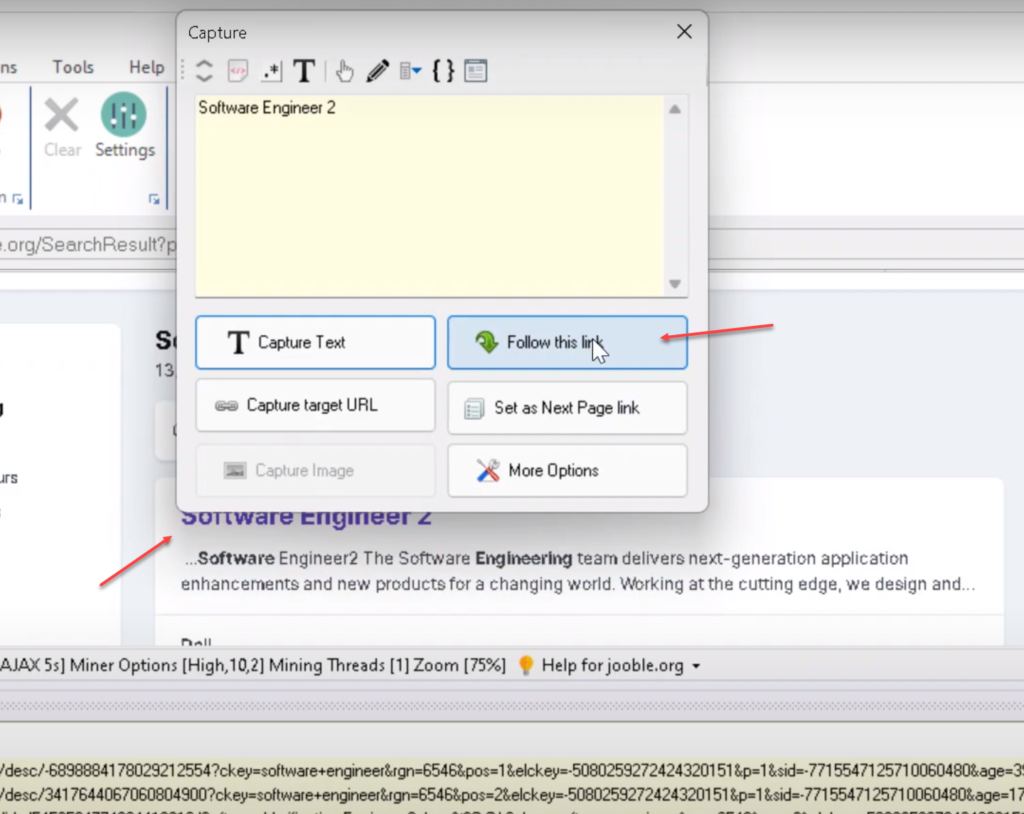
Step 6 : Follow each job listings link to scrape more details
Click on the title/link of the first job listing and select Follow this link option from the resulting capture window. Wait for the job details page to load.
Step 7 : Select data from job details page
Once the job details page is loaded you can click and select more data.
Step 8 : Stop Configuration and Start Mining
Once you have selected all required data, click the Stop button in the Configuration pane. You can now optionally save the configuration so that it can be run later or edited to make changes. Click the Start Mine button to start mining data.
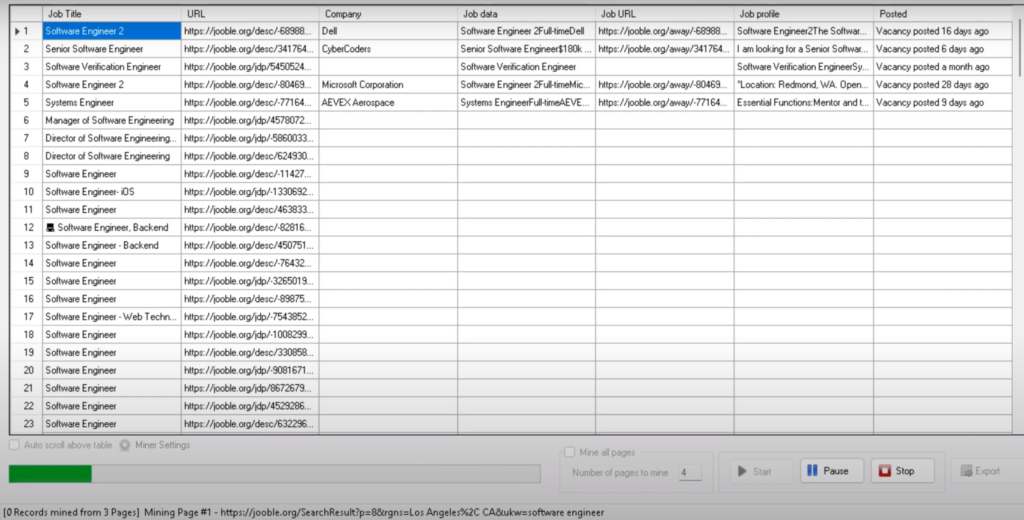
Scraped data can be saved to a file or database by clicking on the Export button in the Miner window.
Try WebHarvy
Download and try the 15 days free evaluation version of WebHarvy. If you have any questions or need technical assistance please do not hesitate to contact our tech support team.