
Glassdoor is a website where employees anonymously review companies which they have worked for. Using Web Scraping, review data from Glassdoor website can be extracted to a local file in your computer or to a database.
Web Scraping is the process of automatically extracting text and images in spreadsheet format from websites. There are no-code web scraping tools like WebHarvy which lets you scrape data from any website via an easy to use, point and click user interface. If you are a developer, you can make use of web scraping libraries (ex: Beautiful Soup for Python) to build a custom web scraper.
How to scrape Glassdoor reviews using WebHarvy?
The following steps explain how you can scrape reviews from Glassdoor using WebHarvy. The data which can be scraped includes (not limited to):
- Review title
- Rating stars
- Pros
- Cons
- Recommended
- CEO Approval
- Business Outlook
Steps to follow
- Download and install WebHarvy in your computer.
- Open WebHarvy and load the Glassdoor reviews page from which you wish to scrape data.
- Start Configuration
- Now, you can click and select any text or image displayed on page for extraction. Clicking on any text or image brings up a Capture window with various options. Select the Capture Text option to scrape the text of the selected item.
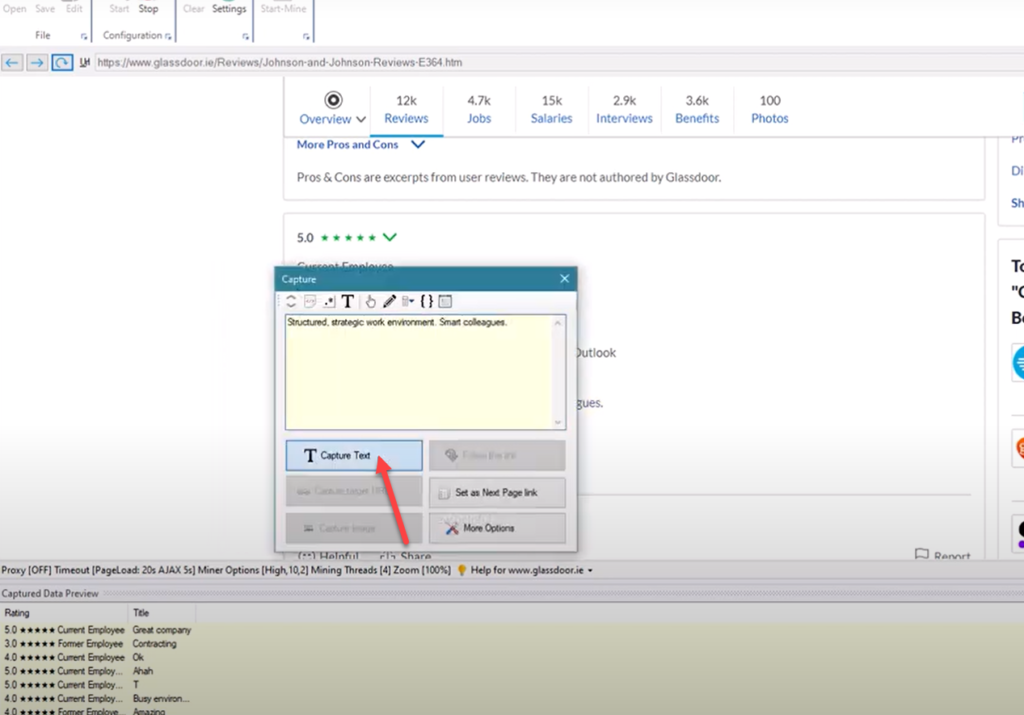
- Details like rating, review title, pros and cons etc. can be selected in this manner. WebHarvy automatically and intelligently finds similar data from subsequent listings.
- To scrape the selected details from multiple pages of review listings, scroll down to the bottom of page and click on the link to load the next page (or direct link to load page number 2). From the resulting Capture window select the Set as Next Page Link option.
- To scrape the tick or cross marks next to Recommended, CEO Approval and Business Outlook we need to convert those images to text. For this we have to make use of WebHarvy’s support for running custom JavaScript code on page
- Click anywhere on the page and select More Options > Run Script from the resulting Capture window. Paste and apply the code given at this link.
- Once the code is applied, you should be able to see YES/NO text near ticks and crosses.
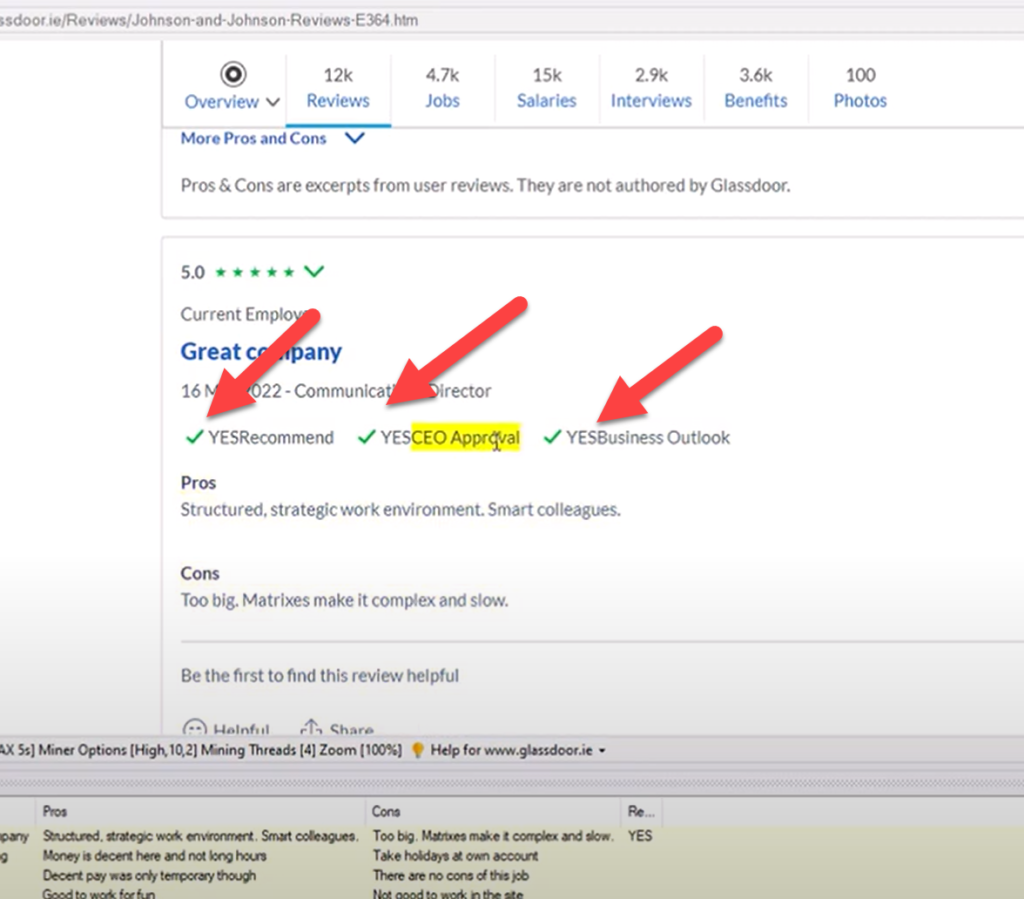
- You can just click over this text and select the Capture Text option to scrape it.
- After all required data has been selected you can stop configuration.
- The configuration can be optionally saved so that it can be run later, scheduled or even edited to make changes.
- Click the Start Mine button to actually start collecting data using the configuration.
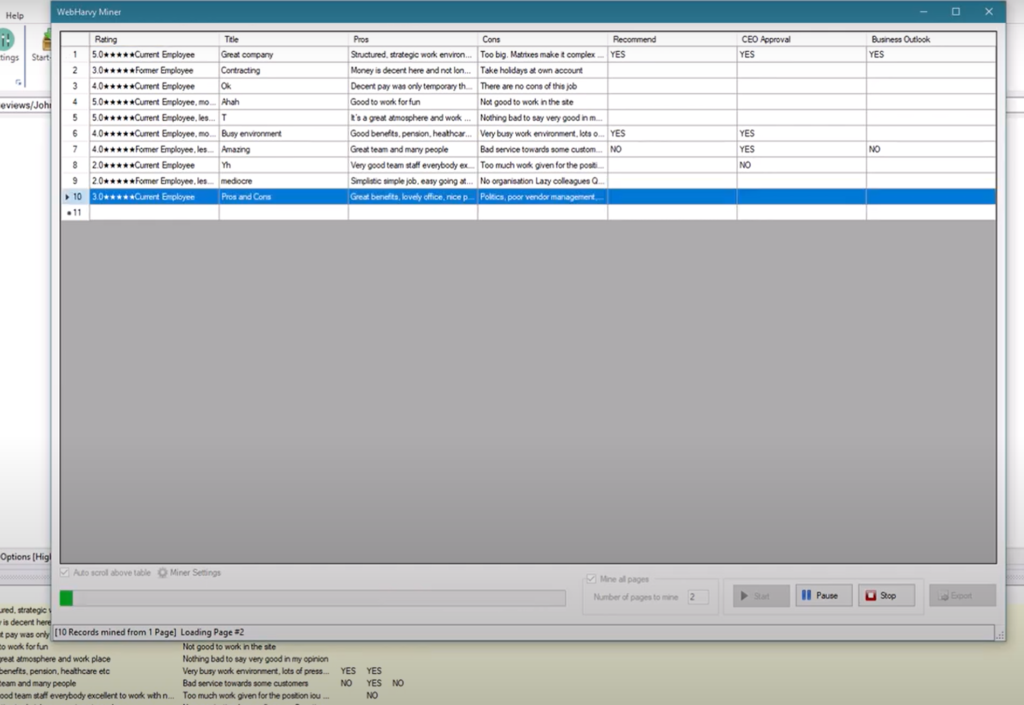
- The scraped data can be saved as a file (csv, excel etc.) or to a database.
Video
The following video shows how WebHarvy can be used to scrape review data from Glassdoor website
Try it youselves
If you are interested, we highly recommend that you download and try using the free evaluation version of WebHarvy. To get started, follow the link below.
Getting started with web scraping using WebHarvy
Need Help?
If you have any questions or need assistance in configuring WebHarvy please do not hesitate to contact us.