
WebHarvy 6.3 comes with support for custom data fields. The following custom data fields can be added to a configuration.
- Current page URL
- Screenshot of currently loaded page
- Date and Time of mining data
- User provided text
Custom data fields can be added by clicking anywhere on the page during configuration and by selecting ‘Add Custom Data’ option under ‘More Options’ from the Capture window.
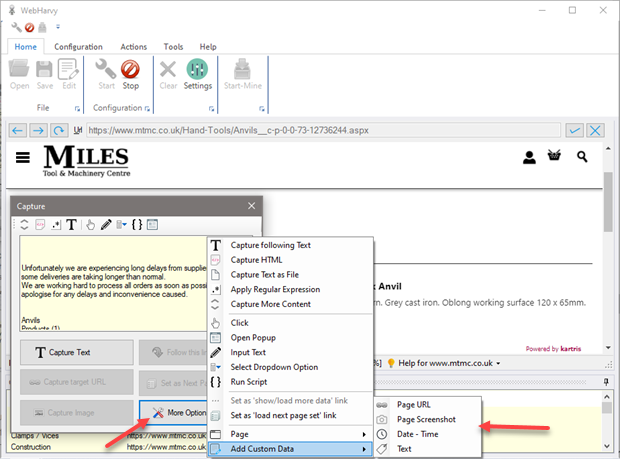
Page URL
Captures URL/address of currently loaded page.
Page Screenshot
Captures screenshot of the currently loaded page and saves it as an image file.
Date Time
Column filled with date-time of mining data.
Text
Column filled with user provided text label.
Other changes
The other changes in this version are:
- Automatically suggests field names for ‘Capture following text‘ option
- ‘Capture following text‘ made faster during configuration
- Supports scraping multiple image URLs automatically. Earlier only multiple image downloads were supported.
- Advanced Miner Options are now saved in the configuration. No need to adjust WebHarvy settings before running configuration with non-default miner options.
- Updated internal browser to the latest possible version.
- Duplicate images are names -001, -002 etc. instead of -1, -2 etc. This helps in sorting images based on name.
- Improved smart help (article, video suggestions based on loaded website)
Questions ?
In case you are new to WebHarvy, we highly recommended that you refer our getting started guide. If you have any questions or need assistance in configuring WebHarvy to scrape data as per your requirement, please do not hesitate to contact us.