WebHarvy 7.6 Released – Updated Browser & Input Text feature
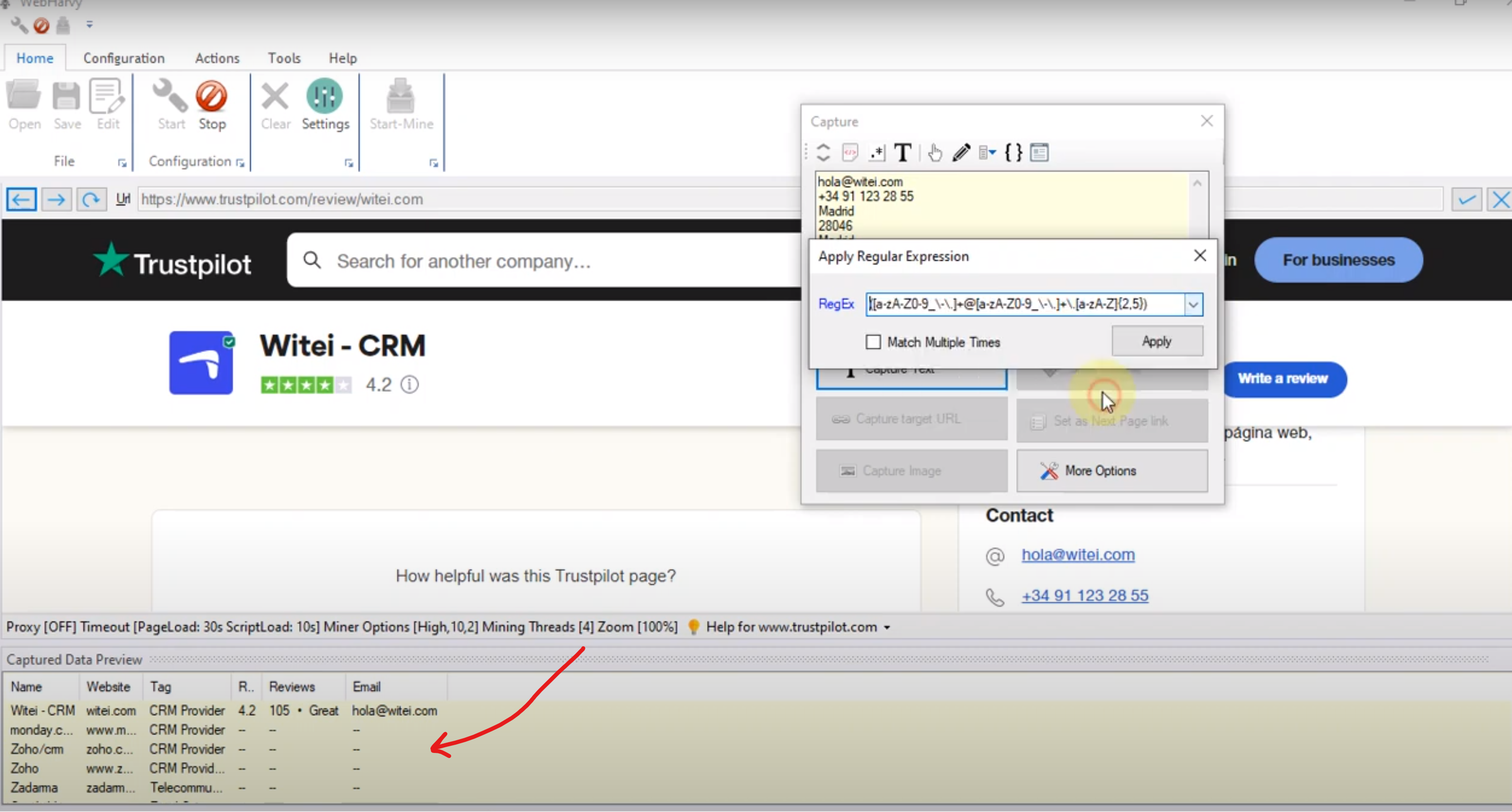
The main change in this version is the updated browser component which handles websites protected by CloudFlare better. With previous versions, many CloudFlare protected websites which display CAPTCHA forms were blocking the user from accessing the website content. This problem has been solved in this version. Another important change is the improvement of the Input … Read more